一个易扩展的负载均衡组件实现
最近在看微博的 motan 的源码,其中使用了 SPI 和模板方法设计模式实现负载均衡组件,觉得比较有意思,所以把它单独拿出来研究,不过 motan 的实现封装得有点复杂,所以我想介绍 SPI、模板方法设计模式及一些常见的负载均衡算法相关的知识,然后再基于这些知识自己实现一个类似的易扩展的负载均衡组件。
1. 模板方法设计模式
先看 wikipedia 中对于 Template method pattern 的介绍。
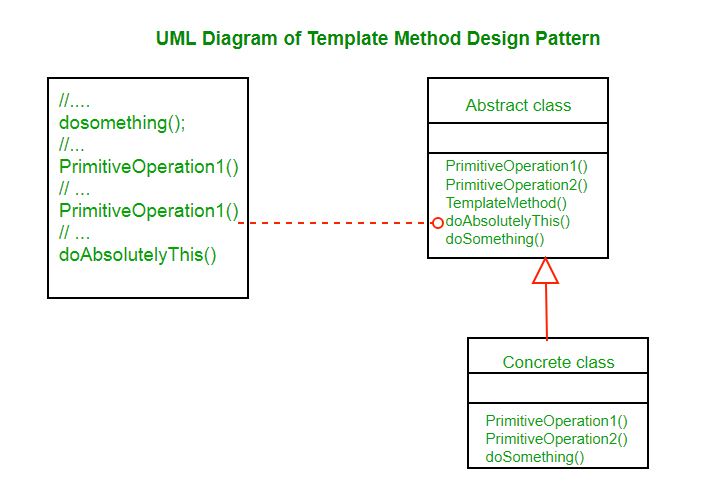
在上面的 UML 类图中,Abstract Class 中定义了一个叫做doAbsolutely 的方法,这个方法定义了行为的骨架,可以理解这是所谓的模板方法,它定义了这个功能的不变的部分,然后变化的部分(PrimitiveOperation1 、 PrimitiveOperation2 和 doSomething)定义成抽象方法让子类去实现。
下面是用 LePUS3 描述的模板方法设计模式图,
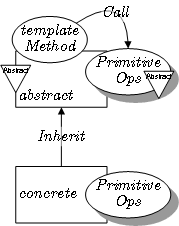
为什么设计这种模式呢?我觉得,对于上述的模板方法,它是一个置于父类的底层方法,子类的要有不同的实现,那么如果不用模板方法的,那么就需要将它设计成抽象方法,然后由子类提供的实现,但是有种情况,如果子类的实现中都有一个通用的处理,比如参数验证等,那么就会存在部分重复的代码,这代码看起来就很招人烦了。
相比之下,使用模板方法,将通用的公共的不变的部分封装到父类中,并通过父类调用变化的抽象方法或者说钩子函数,钩子函数由不同的子类实现并返回结果。这过程想想都觉得很奇妙,举个可能不太生动的例子,如果你玩过索尼的残幅相机,那么可能听过 A6 系列,对于 a6100、a6400、a6600 等等,它们使用的很多零件和功能都是一样的,相同的 2400 万像素传感器,实时跟踪对焦部件以及大部分硬件等,这些可以理解是模板方法,可以作为一个模具之类的东西,不同的相机实现在自己实现不同功能,如快门速度,ISO、视频动态范围、电池等等,具体设计的时候不需要重造模具,只需要将变化的东西接进模具就行了。

综上所述,该设计模式的优点有
- 由于将相同的逻辑封装在父类中,提升了代码的复用性。
- 由于将不同的代码放在子类中,子类通过提供实现扩展不同的行为,提升了扩展性。
- 由于通过父类调用子类的实现才能实现整体的操作,实现了控制反转。
- 软件设计 SOLID 原则中有一点是开闭原则,即认为 “软件体应该是对于扩展开放的,但是对于修改封闭的”。下面这段摘自 知乎文章,意会一下不难理解模板方法设计模式是符合开闭原则的,父类闭合,子类开放。
- 对扩展开放。模块对扩展开放,就意味着需求变化时,可以对模块扩展,使其具有满足那些改变的新行为。换句话说,模块通过扩展的方式去应对需求的变化。
- 对修改关闭。模块对修改关闭,表示当需求变化时,关闭对模块源代码的修改,当然这里的“关闭”应该是尽可能不修改的意思,也就是说,应该尽量在不修改源代码的基础上面扩展组件。
再说模板方法设计模式的缺点,主要是引入了抽象类,需要新增很多子类来提供不同的实现,类的个数及相应的维护成本、系统设计复杂度增加了。
2. 负载均衡
什么是负载均衡呢?大三时我找实习,面试腾讯的时候被问到 Linux 下怎么查看系统的平均负载,那时当即懵了,什么是平均负载呢?支吾了半天没答出来,很是尴尬。
后来看了极客时间倪朋飞的《Linux 性能优化实战》,有一章是《基础篇:到底应该怎么理解“平均负载”》,里面提到:
平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数,它和 CPU 使用率并没有直接关系。
所谓可运行状态的进程,是指使用 CPU 或者正在等待 CPU 的进程,也就是我们常用 ps 命令看到的处于 R 状态(Running 或 Runnable)的进程。
不可中断状态的进程则是正处于内核关键流程中的进程,并且这些进程是不可打断的,比如最常见的是等待硬件设备的 I/O 响应,也就是我们在 ps 命令中看到的 D 状态(Uninterruptable Sleep,也称为 Disk Sleep)的进程。
比如,当一个进程向磁盘读写数据时,为了保证数据的一致性,在得到磁盘回复前,它是不能被其他进程或者中断打断的,这个时候的进程就处于不可中断状态。如果此时的进程被打断了,就容易出现磁盘数据与进程数据不一致的问题。
所以,不可中断状态实际上是系统对进程和硬件的一种保护机制。
因此,可以简单理解为,平均负载其实就是平均活跃进程数。 平均活跃进程数,直观上的理解就是单位时间内的活跃进程数,但实际上是活跃进程数的指数衰减平均值。
在此基础上,可以认为 “负载” 是某段时间内的总活跃进程数。对于平均负载而言:
理想地每个 CPU 上都刚好运行着一个进程,这样每个 CPU 都得到充分利用,比如当平均负载为 2 时,意味着什么呢?
- 在只有 2 个 CPU 的系统上,意味着所有的 CPU 都刚好被完全占用。
- 在 4 个 CPU 的系统上,意味着 CPU 有 50% 的空闲。
- 而在只有 1 个 CPU 的系统中,则则意味着一半的进程竞争不到 CPU。
理想情况下,平均负载应等于 CPU 个数。
当然,我觉得从平均负载上理解负载均衡中的 “负载” 是比较限制视野的,这里只是提供一个供参考的方面,看看 wikipedia 对于负载均衡的定义:

大意是,负载平衡是指将一组任务分配到一组资源(计算单元)上的过程,其目的是使它们的整体处理更加高效。负载平衡技术可以优化每个任务的响应时间,避免某些计算节点不均匀超载,而其他计算节点空闲。再看资源是怎么定义的:

大意是:资源是计算机系统中可用性有限的任何物理或虚拟组件。每一个连接到计算机系统的设备都是一种资源。每个内部系统组件都是一种资源。虚拟系统资源包括文件(具体的文件句柄)、网络连接(具体的网络套接字)和内存区域。资源管理称为资源管理,包括防止资源泄漏(当进程使用完资源时不释放资源)和处理资源争用(当多个进程希望访问有限的资源时)。云计算利用计算资源通过网络提供服务。
而计算机是以进程作为资源开辟的单元的,所以这样看,或许可以认为,负载均衡是指将一组任务分配到各个服务器上力求使得各机器平均负载接近理想的过程。
抽身于理论的角度,我们看看在应用层面怎么认知负载均衡。以 RPC 为例,负载均衡器主要处于客户端,客户端获取到服务列表后,通过负载均衡器选择具体访问的服务地址,从而将 RPC 请求报文转发到相应的服务器。谷歌了一圈之后,我总结到的负载均衡算法大概有下面这些:
Round Robin
有时也叫 Next in Loop,采用轮询法,即设置一个轮,每次返回下一个服务节点,该方法比较简单,但是存在一些缺陷,比如如果两台服务器的硬件配置(CPU、RAM、磁盘等)不一样,但是在同一段时间内使用轮询处理相同的流量,这是不合理的,因为配置更好的服务器理应被分配更多的流量。 然而尽管两台服务器的处理能力不成比例,负载平衡器仍将平均分配请求,久而久之,性能较差的服务器可能因为过载而宕机,这就是所谓的热点问题。
所以这种算法最适用于由具有相同规格的服务器组成的集群。Netflix Ribbon 默认的负载均衡实现就是这种算法,感兴趣可见 这里。
Weighted Round Robin
带权轮询,加权轮循机制与轮循机制相似,尽管将请求分配给节点的方式仍然是循环的,但是某些服务器在总流量中所占份额更大,如规格较高的节点将分配更多数量的请求。但负载均衡器怎么确定服务器的权值呢,权值又以一个怎么样的维度进行定义呢?事实上这些都需要自定义,你需要定义一套根据服务器某个性能指标计算权值,然后可以在设置负载均衡器时为每个节点分配“权重”。
通常,你可以根据服务器实际 CPU 容量指定权重。例如,如果服务器 1 的容量是服务器 2 的 5 倍,则可以为它分配 5 的权重,为服务器 2 分配 1 的权重。
硬件性能(如 CPU 容量)并不是选择 加权循环(WRR)算法 的唯一基础。 有时当一台服务器正在运行一些重要的业务代码时,尽管它的硬件配置比较好,但是你或许会希望它不要处理太多的其他请求,以免过载从而影响重要的业务。
Random
顾名思义,该算法通过随机匹配客户端和服务器,即使用基础随机数生成器。在负载均衡器收到大量请求的情况下,随机算法将能够将请求平均分配给节点。因此,与 Round Robin 一样,对于由具有相似配置(CPU,RAM等)的节点组成的集群,随机算法就足够了。
Least Connections
最少连接,在某些情况下,即使集群中的两台服务器具有完全相同的规格,一台服务器仍然可以比另一台服务器更快地过载。一种可能的原因是连接到服务器 2 的客户端保持的连接时间比连接到服务器 1 的客户端保持的时间长得多。这可能会导致服务器 2 中的当前总连接堆积,而服务器 1 中的总连接(客户端在较短时间内连接和断开连接)实际上将保持不变。 结果,服务器 2 的资源可以更快地用完。
在这种情况下,最少连接算法会更合适。 该算法考虑了每个服务器具有的当前连接数。当客户端尝试连接时,负载平衡器将尝试确定哪个服务器的连接数最少,然后将新连接分配给该服务器。
Weighted Least Connections
带权最少连接,加权最少连接算法对最少连接的作用类似于加权轮询对轮询的作用。即它基于每个服务器的相应容量引入“权重”组件。 就像在加权循环中一样,你必须预先指定每个服务器的 “权重”。现在,要实现 “加权最少连接” 算法的负载平衡器会考虑两件事:每个服务器的权重/容量以及当前连接到每个服务器的客户端的当前数量。
当然还有很多,比如说著名的一致性哈希算法、基于服务端流量监控的Least traffic,还有就是 Perlbal 中使用 HTTP OPTIONS 请求报文获取各个服务器的交互延迟,然后再根据延迟大小决定选择选择哪个服务器。
当然,不同的算法有着不同的特点,从而导致其应用场景也不同,以 RPC 为例,我之前想给 motan 添加一个 Least Connections 负载均衡器实现(issue 传送门),项目维护者给我以下的建议:
- RPC一般都是长链接,很多场景下服务端链接数不能很好的代表服务节点的压力;
- LB 算法要尽量简单,避免某些未知情况下导致线上流量不可控;
- 复杂的流量策略,最好是由类似策略中心来统一控制。
3. 负载均衡组件实现(上)
负载均衡器分为软硬件两种形式,下面介绍如何实现软件形式的负载均衡器。考虑 RPC 的应用场景,客户端动态代理在用户无察觉的情况下封装调用信息,在此过程中需要选择一个具体的服务节点进行报文转发,这时它会根据服务 URI 去注册中心查询对应的 IP 集合,
- 然后判断这个集合是不是空的,若是则抛出异常之类的;
- 否则再看该集合是不是只存在一个服务节点且节点处于可用的状态,是的话则将请求转发到该服务节点;
- 如果服务节点不止一个,那么就再进一步根据某种负载均衡算法在服务列表中选择一个合适的节点进行转发。
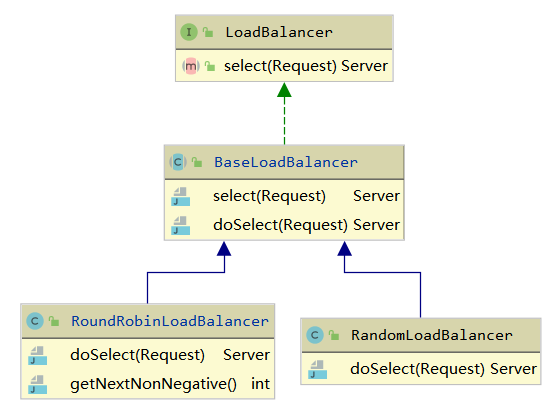
可以看到,上面这些步骤中,根据某种负载均衡算法进行服务选择的过程时可变的部分,而其他部分是不变的,显然可以使用上面介绍的模板方法模式进行设计。我们可以按以下的步骤来
- 写一个
LoadBalancer接口,其中定义接口方法select - 写一个
BaseLoadBalancer的抽象类,在其中实现LoadBalancer的select方法,实现到上述的第三步的时候调用本类的抽象方法doSelect方法。 - 再写几个
BaseLoadBalancer的实现类,在doSelect方法中实现具体的节点选择算法。
上述各个类的关系如下类图所示:
为了避免堆砌代码,我截了上面几个类的关键代码片段,想看完整的代码可以点 这里。

ok,打完这一套之后,我们已经实现了符合开闭原则的 LB,那么怎么获取到这些 LB 对象呢?也许你会这样写
|
|
但是如果某天使用随机的做法已经不符合系统的要求了,我需要换用 RR 了,那如何是好呢?有人说了,这不简单,直接在程序里改不就得了,将 RandomLoadBalancer 换成 RoundRobinLoadBalancer,反正面向接口编程不就是这样玩的吗?
可以是可以,不过按我的理解来说,当你的程序成熟到一定程度时,上面这段代码(不一定这样写,主要是获取 LB 的方式)也应该符合开闭原则(当然前提是 u r not coding shit,这好像还不要紧,如果 u r enjoying coding shit,那当我没说)。
4. SPI 介绍
SPI 英文全称为 Service provider interface,看到 wikipedia 中对它的介绍如下所示:
Service Provider Interface (SPI) is an API intended to be implemented or extended by a third party. It can be used to enable framework extension and replaceable components
大意是,SPI 是一种 API 定义,可被第三方实现或扩展,常被用于框架中实现扩展插件或可替换的组件。在 JDK 中涉及的类主要是 java.util.ServiceLoader,对此 Java 的官方文档 中介绍到:
A service is a well-known set of interfaces and (usually abstract) classes. A service provider is a specific implementation of a service. The classes in a provider typically implement the interfaces and subclass the classes defined in the service itself. Service providers can be installed in an implementation of the Java platform in the form of extensions, that is, jar files placed into any of the usual extension directories. Providers can also be made available by adding them to the application’s class path or by some other platform-specific means.
其中提到两个需要搞清楚的概念:
- service:一组接口或抽象类
- service provider:service 的具体实现,可以以 jar 包的形式安装到 Java 平台中。
For the purpose of loading, a service is represented by a single type, that is, a single interface or abstract class. (A concrete class can be used, but this is not recommended.) A provider of a given service contains one or more concrete classes that extend this service type with data and code specific to the provider. The provider class is typically not the entire provider itself but rather a proxy which contains enough information to decide whether the provider is able to satisfy a particular request together with code that can create the actual provider on demand. The details of provider classes tend to be highly service-specific; no single class or interface could possibly unify them, so no such type is defined here. The only requirement enforced by this facility is that provider classes must have a zero-argument constructor so that they can be instantiated during loading.
service 应该使用单一类型表示,即接口或抽象类(可以使用具体类,但不建议这样做)。一个 service 可以有很多 provider 实现,SPI 对于这些实现没有很多约束,只要它能满足特定的请求和实现一定的功能即可,唯一的硬性要求是它们里面必须要有一个无参构造函数,这样它们就可以在加载期间被实例化。
A service provider is identified by placing a provider-configuration file in the resource directory
META-INF/services. The file’s name is the fully-qualified binary name of the service’s type. The file contains a list of fully-qualified binary names of concrete provider classes, one per line. Space and tab characters surrounding each name, as well as blank lines, are ignored. The comment character is'#'('\u0023', NUMBER SIGN); on each line all characters following the first comment character are ignored. The file must be encoded in UTF-8.
在实现 service provider 后,需要在资源目录 META-INF/services 中的一个以相应 service 命名的文件中写上它的全限定类名。这个文件中包含对应 service 的所有具体服务提供类的全限定类名,每个一行,每个名称周围的空格、制表符以及空白行将会在加载时被忽略。注释字符为#' (\u0023,有符号整数)。在每行中,第一个注释字符之后的所有字符都将被忽略。该文件必须用 UTF-8 编码。
If a particular concrete provider class is named in more than one configuration file, or is named in the same configuration file more than once, then the duplicates are ignored. The configuration file naming a particular provider need not be in the same jar file or other distribution unit as the provider itself. The provider must be accessible from the same class loader that was initially queried to locate the configuration file; note that this is not necessarily the class loader from which the file was actually loaded.
如果一个 service provider 在配置文件中出现了超过一次,则多余的将被忽略。命名特定 provider 的配置文件不能与 provider 本身在同一个 jar 文件中。provider 必须可以被最初查询以定位配置文件的同一个类加载器访问;,但注意,这并不必要是实际加载配置文件的类加载器(或许可以从双亲委派模型的角度解释)。
Providers are located and instantiated lazily, that is, on demand. A service loader maintains a cache of the providers that have been loaded so far. Each invocation of the iterator method returns an iterator that first yields all of the elements of the cache, in instantiation order, and then lazily locates and instantiates any remaining providers, adding each one to the cache in turn. The cache can be cleared via the reload method.
Service loaders always execute in the security context of the caller. Trusted system code should typically invoke the methods in this class, and the methods of the iterators which they return, from within a privileged security context.
Instances of this class are not safe for use by multiple concurrent threads.
Unless otherwise specified, passing a
nullargument to any method in this class will cause a NullPointerException to be thrown.
provider 是按需懒定位和实例化的。service loader 会缓存加载过的 service,每次调用 iterator 方法都会返回一个迭代器,该迭代器首先按实例化顺序生成缓存的所有元素,然后惰性地定位和实例化剩余的不在缓存中的 provider,依次将每个 provider 添加到缓存中。可以通过 reload 方法清除缓存。
service loader 总是在调用者的安全上下文中执行。受信任的系统代码通常应该从特权安全上下文中调用该类中的方法以及它们返回的迭代器的方法(见下文的 ensureDriversInitialized 方法中的AccessController.doPrivileged)。ServiceLoader 类的实例对于多个并发线程的使用是不安全的。
5. 负载均衡组件实现(下)
下面使用静态工厂的方式提供 LoadBalancer,具体获取LoadBalancer 的工作交给 SPI。
|
|
不过这样还不行,还需要注意在 resources 目录下创建 META-INF/services 目录,在里面创建一个以服务接口命名的文件。
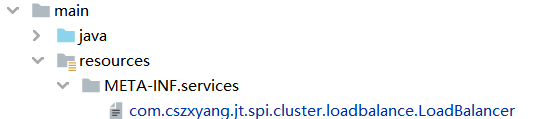
然后在里面写上具体的接口实现的全限定类名,虽然还没有跟踪源码看 SPI 的加载过程,但想想其运作过程不外乎是加载这个目录下的配置文件,然后根据实现类名,利用反射创建实现类对象。
com.cszxyang.jt.spi.cluster.loadbalance.RoundRobinLoadBalancer
com.cszxyang.jt.spi.cluster.loadbalance.RandomLoadBalancer
现在我们来写个简单的客户端调用测试一下,在此之前先在 BaseLoadBalancer 中初始化三个服务器信息。
|
|
可以看到 RR 的输出信息如下
Server(ip=127.0.0.1, port=9090)
Server(ip=127.0.0.1, port=443)
Server(ip=127.0.0.1, port=80)
Server(ip=127.0.0.1, port=9090)
Server(ip=127.0.0.1, port=443)
Server(ip=127.0.0.1, port=80)
Server(ip=127.0.0.1, port=9090)
Server(ip=127.0.0.1, port=443)
Server(ip=127.0.0.1, port=80)
Server(ip=127.0.0.1, port=9090)
现在我们改变resources/META-INF/services 中定义的实现顺序,让RandomLoadBalancer 排在第一个,然后得到的运行输出信息如下所示。
Server(ip=127.0.0.1, port=80)
Server(ip=127.0.0.1, port=443)
Server(ip=127.0.0.1, port=80)
Server(ip=127.0.0.1, port=443)
Server(ip=127.0.0.1, port=9090)
Server(ip=127.0.0.1, port=9090)
Server(ip=127.0.0.1, port=9090)
Server(ip=127.0.0.1, port=80)
Server(ip=127.0.0.1, port=80)
Server(ip=127.0.0.1, port=80)
6. SPI 扩展
看完怎么基于 SPI 进行负载均衡器实现配置后,再来看看它在其他地方的应用,其实在 JDBC 方面,我们先引入两个依赖。
|
|
然后我们点开 IDEA 的 External Libraries 查看 jar 包源码,会发它们在 META-INF/services 中都有个叫做 java.sql.Driver 的文件。
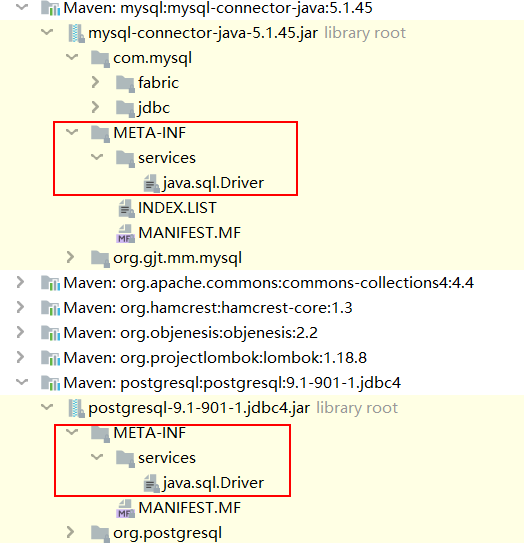
根据上面的知识可以知道,java.sql.Driver 是一个接口,实际上是 JDBC 的驱动接口,mysql 和 postgresql 为该接口提供各自的实现。可以看到 mysql-connector-java:5.1.45 中 META-INF/services 中指明两个 provider。
com.mysql.jdbc.Driver
com.mysql.fabric.jdbc.FabricMySQLDriver
而 postgresql:9.1-901-1.jdbc4 的 META-INF/services 中只有一行内容
org.postgresql.Driver
我们写个测试获取所有的驱动实现。
|
|
然后简单调用一下:
|
|
可以看到打印的信息如下所示,说明不管什么驱动实现,只要遵循 SPI 的玩法,都能被自动创建和加载:
com.mysql.jdbc.Driver@497470ed
com.mysql.fabric.jdbc.FabricMySQLDriver@63c12fb0
org.postgresql.Driver@b1a58a3
其实在 JDBC 4.0 之前,请求连接之前需要使用反射来加载驱动实现,如对于 MySQL,需要这样写 Class.forName("com.mysql.jdbc.Driver"),但是我们在 Oracle Doc 中对 JDBC 4.0 和 JDBC 4.1 地介绍中知道, 自 JDBC 4.0 起能够自动加载 JDBC 驱动,不需要手动注册,在连接时 DriverManager 会找到合适的 JDBC 驱动。
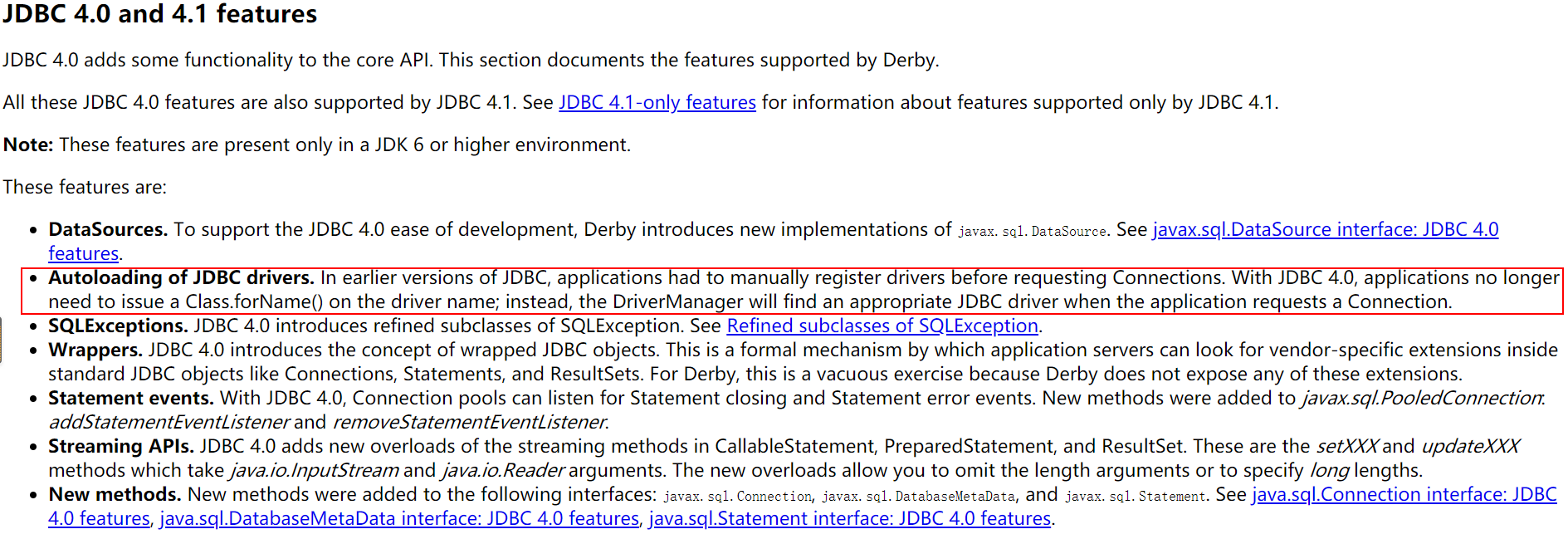
java.sql.DriverManager 是 JDBC 用于注册和管理连接的工具类,下面引用所示的是 Oracle API Doc 中对于它的介绍,关键点在于其中获取连接和驱动的方法在 JDBC 4.0 开始已经被 Service Provider 机制增强了,第三方的驱动实现只需要在 jar 包的资源目录下的 META-INF/services/java.sql.Driver 文件中定义,就能被自动加载进来。
The
DriverManagermethodsgetConnectionandgetDrivershave been enhanced to support the Java Standard Edition [Service Provider](https://docs.oracle.com/javase/8/docs/technotes/guides/jar/jar.html#Service Provider) mechanism. JDBC 4.0 Drivers must include the fileMETA-INF/services/java.sql.Driver. This file contains the name of the JDBC drivers implementation ofjava.sql.Driver. For example, to load themy.sql.Driverclass, theMETA-INF/services/java.sql.Driverfile would contain the entry:
那么具体是怎么实现的呢,我们可以点开 java.sql.DriverManager 的源码,直接搜 ServiceLoader,我们看到逻辑都在下面这个 ensureDriversInitialized 方法中。
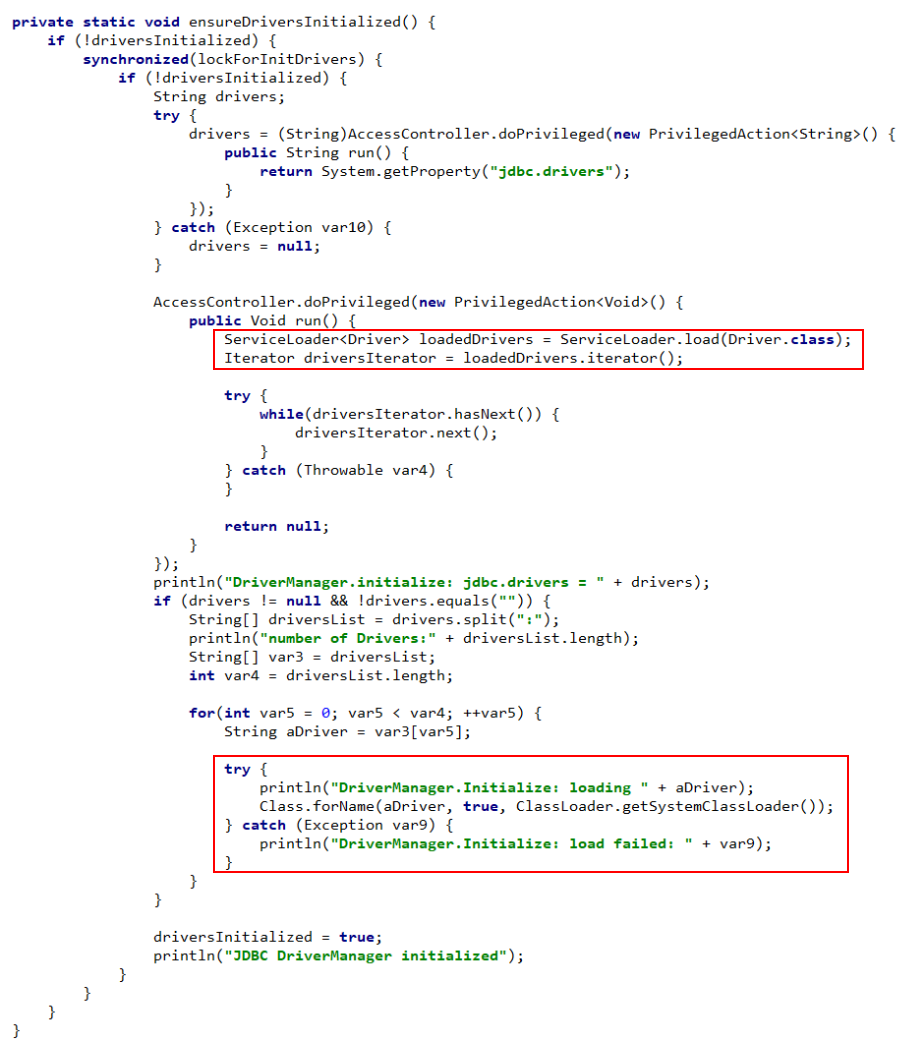
可以看到其中使用 ServiceLoader 加载 classpath 下以及 jar 包中所有的 META-INF/services 目录下的java.sql.Driver 文件,并找到具体的实现类的名字,然后创建 Class 对象,没有看到创建具体的 Provider 对象的逻辑,但是上面提到调用 iterator 方法会基于缓存选择性地创建对象,具体逻辑看 iterator 方法,在此不深究。
7. 总结
上面这一套就是 motan 对于负载均衡器的实现的基本原理,其他插件的实现也类似,不过相比之下,它封装得更深,比如说对 SPI 的封装(涉及到 SpiData 注解)等,估计是考虑到的问题更多。
然后我看 dubbo 里面也使用了 SPI 机制,不过它更狠,干脆自己实现一套 SPI 机制,并且在此基础上把类似 Spring IoC 的容器化技术也应用进去了。
最后简单总结一下,本文介绍了模板方法设计模式(特点、优缺点、应用场景等)、负载均衡的概念及常见的负载均衡算法、还介绍了 SPI 的概念和应用,同时在这些知识前提下实现了一个符合开闭原则的算是比较优雅的负载均衡器组件。
以上,希望对你有所帮助,如果你有什么想说的,欢迎在评论区给我留言。