写给黑客的 Java 编译器不完全指南
我的毕业设计做的是一个在线集成开发环境,我给它取了个名字,叫 olycode,意思大概是online coding。截止目前,它支持在线运行 Java、Python 和 Lua 代码,该项目现在运行在我的服务器上,可以点 传送门 过去玩玩,完整的工程代码也已经上传到了 Github,感兴趣的朋友可以点 这里 去看看。
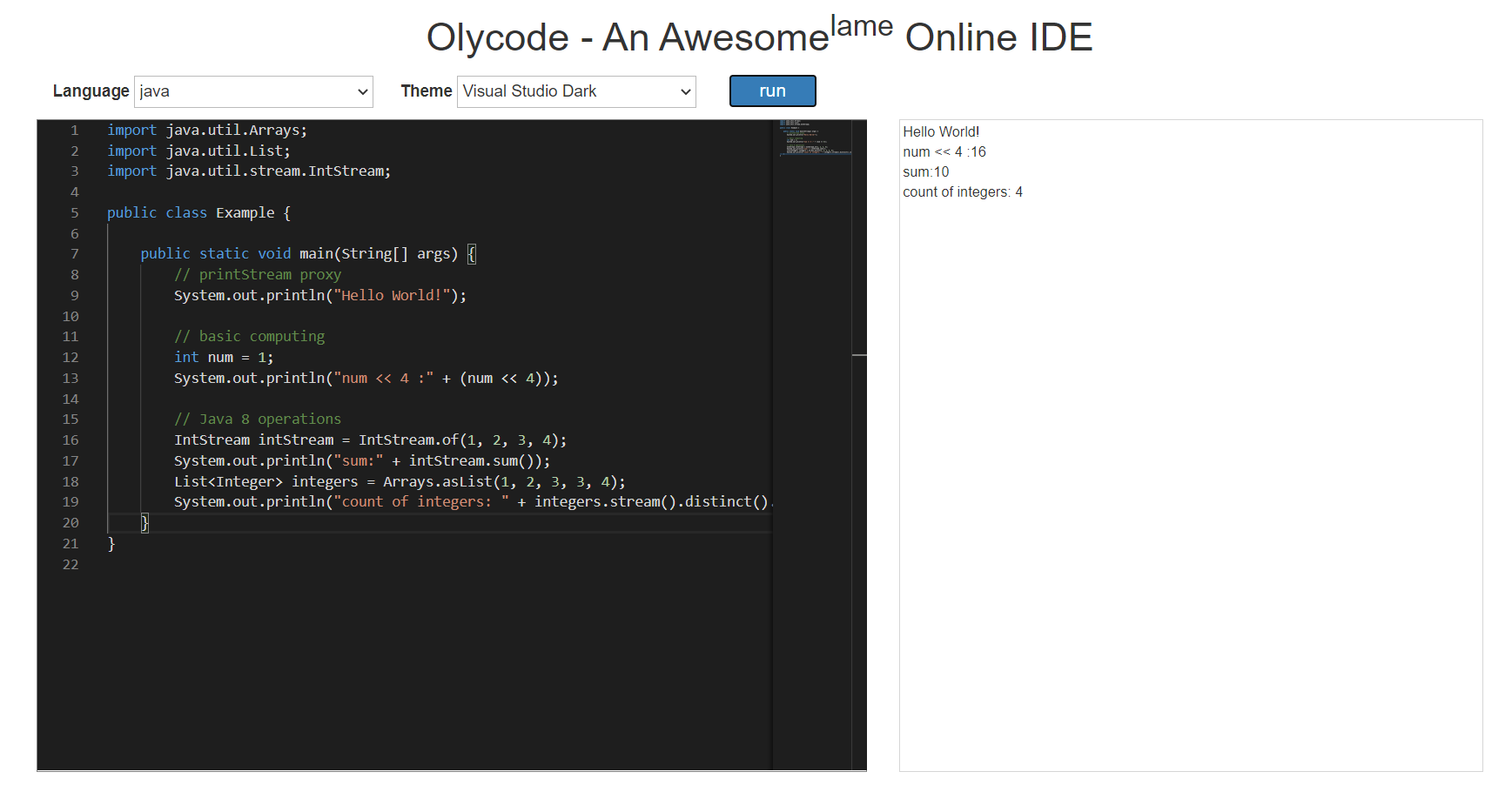
首先说下为什么我要做这样的一个项目,主要有三点:
-
写腻了增删查改的管理系统
-
身边的安全大佬写的是漏洞扫描器、安全狗之类的专业相关的犀利玩意,不过我玩不来,之前写过一个密码学相关的东西(Github传送门),做的是教学演示之类的,能够输出每一步的比特或字节位在加解密子过程中的变化,虽然算法那块都是我自己基于源文档实现的,但是总觉得要把教学效果做好对界面设计的要求很高,那岂不是我的毕设工作都集中在前端的代码上了?显然这不是我想要。
-
一个 CS 菜鸡的编译器情结:如果你看过《程序员的呐喊》这本书,会发现作者 Steve Yegge 花了一部分篇幅去介绍编译原理方面知识的重要性,并且在最后下了这么一个定义:“编译原理是计算机科学第二重要的课程。” 看到这里你或许会说,切,才第二,不过第一重要的课程是什么呢?答案居然是 Typing,这直接让我对这本书的豆瓣评分加了一颗星。
有时候我在想,不管是前端、后台还是客户端,在工作中很多时候都是在用别人的工具拧螺丝。我总感觉 CS 的知识浩如烟海,自己就像一个迷失在海边的小人,很多时候都在为捡到被海浪冲上岸的贝壳而满心雀跃,却不知深海底下有什么样迷人的风光和发生着什么样光怪陆离的故事。
所以还是准备能在学校的期间做点有意思的事情(当然如果能做喜欢的工作的话,那该有多幸福),而说到能与编译原理沾边的又具备一定实用价值的东西,我第一个想到的就是在线 IDE。
在此啰嗦多几句,在编译原理的学科中有三本不得不提的书,龙虎鲸三兄弟,我去年年底买了虎书打算折腾一下的,结果遇上疫情,现在它已经在学校宿舍吃了几个月灰。
- 龙书:Alfred V.Aho / Ravi Sethi / Jeffrey D.Ullman / Monica S. Lam 的《Compilers: Principles, Techniques, and Tools》
- 虎书:Andrew W.Appel / Jens Palsberg 的《Modern Compiler Implementation in C》
- 鲸书:Steven S.Muchnick 的《Advanced Compiler Design and Implementation》
接下来简单介绍下这个项目是怎么做的,Python 部分使用的是三方库 jython 实现,纯粹是调 API,非常简单。Lua 部分则是基于 Lua 官方文档及张秀宏的 《自己动手实现 Lua - 虚拟机、编译器和标准库》 一书中实现的小编译器及虚拟机实现的,虽然用 C 语言写的 Lua 比较短小精悍,但这部分的复杂度和工作量还是比较大的,在此不展开详述。
Java 部分也比较有趣,由于 olycode 是用 Java 写的,所以我干脆使用 JDK 的 tools.jar 中提供的 javac 工具进行源码编译,虽然曾经想过重造轮子写个 Java 虚拟机,事实上张秀宏的 《自己动手写Java虚拟机》 一书中也已经手把手教人写个小 VM 了,但是想想整了半天最后只能写出个打印 hello world 的玩具,其实用性方面还是过于欠缺,而且光有 VM 还不行,之前下过 OpenJDK 的源码,瞄了一眼 javac(事实上 javac 是用 Java 写的,这让我很惊讶),其代码规模实在让我望而却步。另外,既然已经动手实现 Lua,就毕业工程设计层面来看,其研究价值和工作量已经够了,不如直接用类库,保证 Java 语言的在线编程需要的完整的语法都能被用到。
点开 tools.jar 的源码,可以看到在 tools 目录下有很多子目录,里面还提供了 javap、javah 等工具,今天主要聊聊比较有意思的 javac。
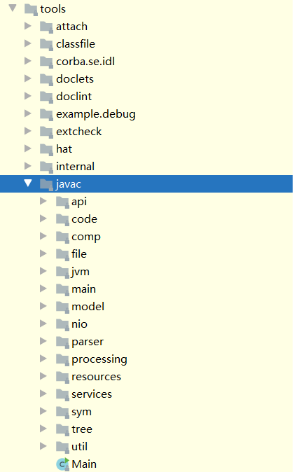
Java Compiler API
Java Compiler API 最早在 1998 年提出的 JSR 199: JavaTM Compiler API 需求文档中定义,通过它我们可大致了解这个开放的 API 中 Java Compiler 的一些特性:
- 基于 NIO 进行扩展出一套抽象的文件系统,允许用户从传统文件系统、jar 包或内存读取源代码。
- 支持以结构化数据的形式从编译器返回诊断信息。
再看为什么需要设计这套编译器 API:
- JSP 代码最终需要编译成字节码,此过程需要将依赖编译器支持,如果能实现运行时编译,将可以避免使用另开进程的方式生成字节码。
- IDE 开发者希望能够方便地处理用户编写的源代码。
在 2006 年,Java SE 6.0 发布,代号 Mustang(野马),相关的代码随之问世。
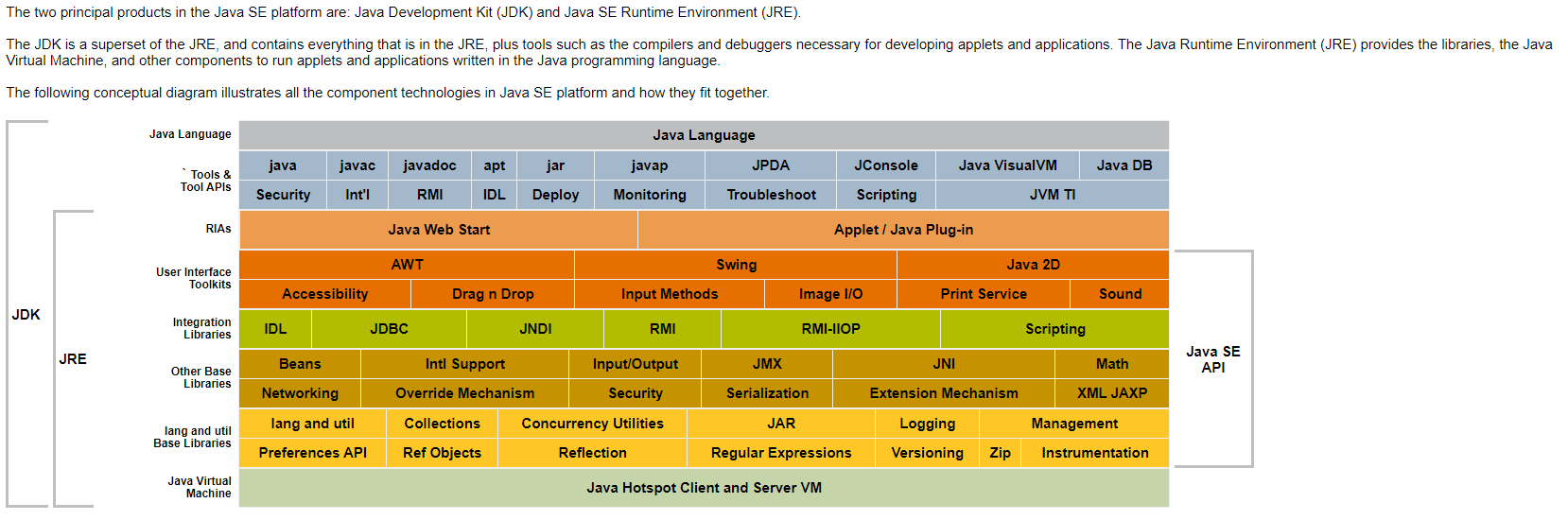
说白了,这套东西就是为了能在运行时实现 Java 代码的动态编译,除此之外,javac 包下还有 AST 分析相关的 Tree API 和编译期注解处理相关的 APT API,后续将一一介绍。
Java Compiler API 定义在 rt.jar 中,既然说是 API ,自然先看绿色标记的接口,主要提供几个接口:
JavaCompiler:Java 编译器的抽象表示,可通过 JavaCompiler compiler = ToolProvider.getSystemJavaCompiler(); 获取到接口实现实例,不过这一句可能会抛异常,之前我把 olycode 打包丢到自己的服务器上,通过命令行执行java -jar olycode.jar,然后就吃了下面这个异常,定位到编译器类的第 63 行刚好就是这句。
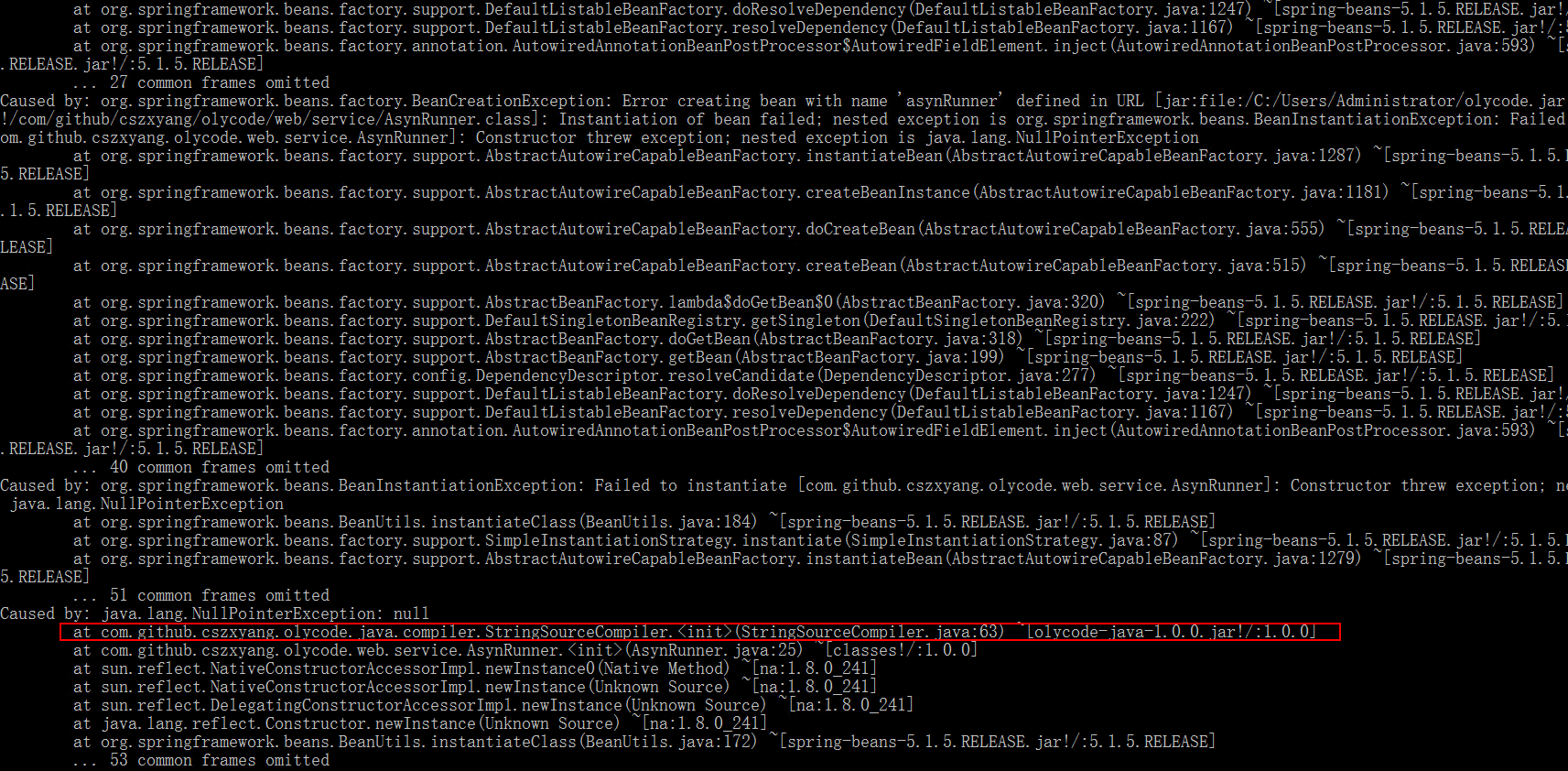
经验证明需要检查在自己的 PATH 路径下是否有 tools.jar 这个包,实在不行的话就将切换到 JDK 目录下再执行 java 命令。如果想省事的话,直接 Maven 依赖的方式引入也无妨,不过看网上有人说不同的操作系统中的 systemPath 可能会有些出入,具体我没比较过,读者知悉。
|
|
JavaCompiler 依赖于两个服务:诊断监听器(diagnostics listener)和文件管理器(file manager)。
编译器可能在编译期间生成诊断信息(diagnostics,例如,错误消息)。如果提供了诊断监听器(diagnostics listener),则将向监听器提供诊断信息。如果没有提供监听器,除非另有规定,不然诊断信息将以未指定的格式格式化并写入到默认输出对象中去,即 System.err。即使提供了诊断监听器,一些诊断信息未必适合写入 Diagnostic 对象中,这些信息最终还是会写入默认的输出。
每个编译器实例有一个相关联的标准文件管理器(standard file manager),它是该编译器工具内置的文件管理器。可通过调用 StandardJavaFileManager fileManager = compiler.getStandardFileManager(null, null, null); 获得。
在这个包中有许多用来简化 SPI 的实现和定制编译器行为的类和接口,下面展开介绍:
StandardJavaFileManager:每个实现这个接口的编译器都提供了一个标准的文件管理器来操作常规文件。StandardJavaFileManager 接口定义了从常规文件创建文件对象的方法。
标准文件管理有两个作用:
- 用于定制编译器如何读写文件的构造块
- 支持在多个编译任务之间共享文件
可通过重用文件管理器的方式来减少扫描文件系统和读取 jar 包的开销。尽管可能没有减少开销,一个标准的文件管理器必须与多个序列化的编译任务一起工作,如下面的代码片段所示,其中 compilationUnits2 重用 fileManager 以是的能够用上缓存。
|
|
DiagnosticCollector:用于收集诊断信息,实例代码如下所示:
|
|
ForwardingJavaFileManager, ForwardingFileObject, 和 ForwardingJavaFileObject:子类化不能用于覆盖标准文件管理器(standard file manager)的行为,因为标准文件管理器是通过调用编译器上的 getStandardFileManager方法而不是通过调用文件管理器的构造函数创建的。所以应该使用委托(delegation)的方式,将标准文件管理器对象作为参数进行传递以在其基础上扩展自定义的文件管理器的行为。例如,考虑如何在调用JavaFileManager.flush()时将所有调用记录下来,代码实现如下所示:
|
|
SimpleJavaFileObject:这个类提供了一个基本的文件对象实现,我们可以继承并扩展其行为并在此基础上创建文件对象。简单理解就是,在这一套编译系统中,文件管理器仅对能识别的文件对象进行操作,为此我们的源码需要使用规范的形式表示,例如对于一串字符串源码,可以丢进一个 jar 包中,然后再叫文件管理器去读取这个 jar 包;可以将源码丢到内存区域中,然后叫文件管理器去相应的内存取数据,不管源码以什么的形式存在,只要对其的操作行为能够被文件系统认可就行。例如,下面介绍如何定义一个包裹字符串形式源码的文件对象:
|
|
看完这一套之后我们可以进行源码的编译了
|
|
其中 CompileResult 是我自己定义的一个编译结果包裹类,getClassName方法中使用了正则表达式识别源代码的类的名字,然后组装成一个 <String, JavaFileObject> 形式的键值对丢到一个哈希表里面缓存起来,为了保证并发安全,这里使用了 ConcurrentHashMap,并且在自定义的文件管理器中定义写入编译结果的行为。
|
|
打完这一套之后,我们可以写个测试程序编译一段字符串源码看看:
|
|
运行后可以看到输出如下所示:
|
|
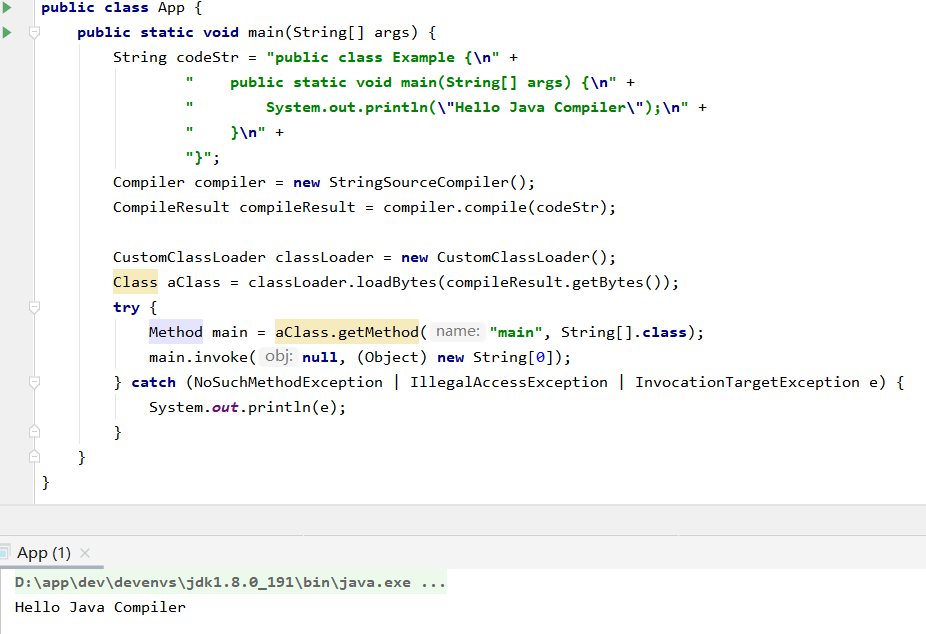
这不就是我们亲切的字节码嘛,那要怎么才能看到最终的执行结果呢?我们可以通过类加载的方式,将字节码加载进 JVM 内存成为一个 Class 对象,然后再通过反射调用 Example 类中的 main 方法。
|
|
然后我们进行反射调用,可以看到在控制台打印了我们想要的信息:
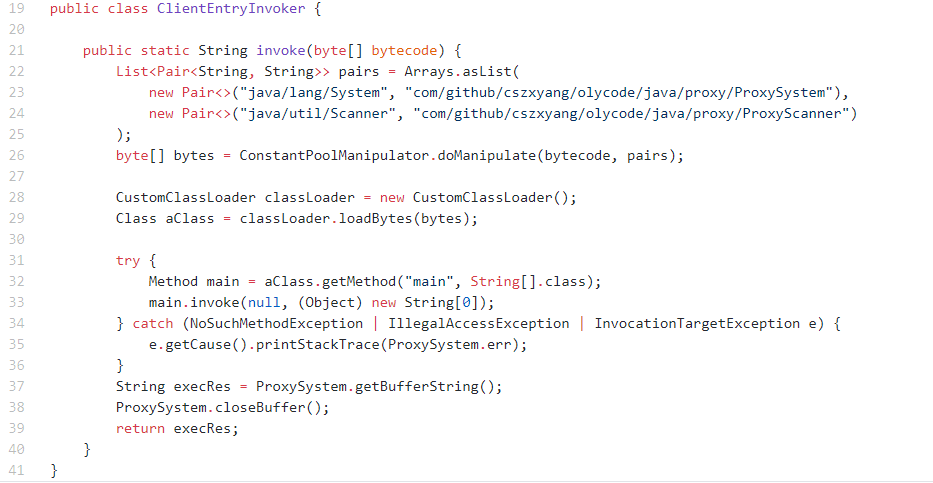
不过在 olycode 中我这里做得复杂一些,先通过修改字节码将常量池中的字面量 java/lang/System 和 java/util/Scanner 分别替换为我定义的 com/github/cszxyang/olycode/java/proxy/ProxySystem 和 com/github/cszxyang/olycode/java/proxy/ProxyScanner,为什么需要这样做呢?
我使用别人的在线 IDE 时,经常需要打印一些东西,对于 Java 程序,自然用的最多的就是调System.out.println方法了,但是点开其源码,你会发现:

没错,用了 synchronized 锁住当前的 System.out 对象,设想如果以后一不小心我的小olycode火起来了,用户量噌噌噌地上去了,那么假如并发量很大的话,这里将会成为一个性能瓶颈,尽管 《Java并发编程的艺术》 中提到 JDK 1.6 后对锁做了一些优化,如锁消除、锁粗化、轻量级锁和偏向锁等,但且抛开优化失效的情况,我认为如果同步等待队列很长的话,还是难顶,所以干脆将java/lang/System 和 java/util/Scanner 拷出来魔改,以java/lang/System 为例,将其中的 PrintStream 类似的 out 对象改成自定义的 ThreadLocalPrintStream ,其中使用 ThreadLocal 包裹一个 java.io.ByteArrayOutputStream 对象,通过 ThreadLocal 为每条线程维护私有的输出对象,这样就能避免多线程同步等待的性能问题啦,具体的逻辑不在这里展开了,感兴趣的朋友可以去看看 olycode 的源码。
AST 分析
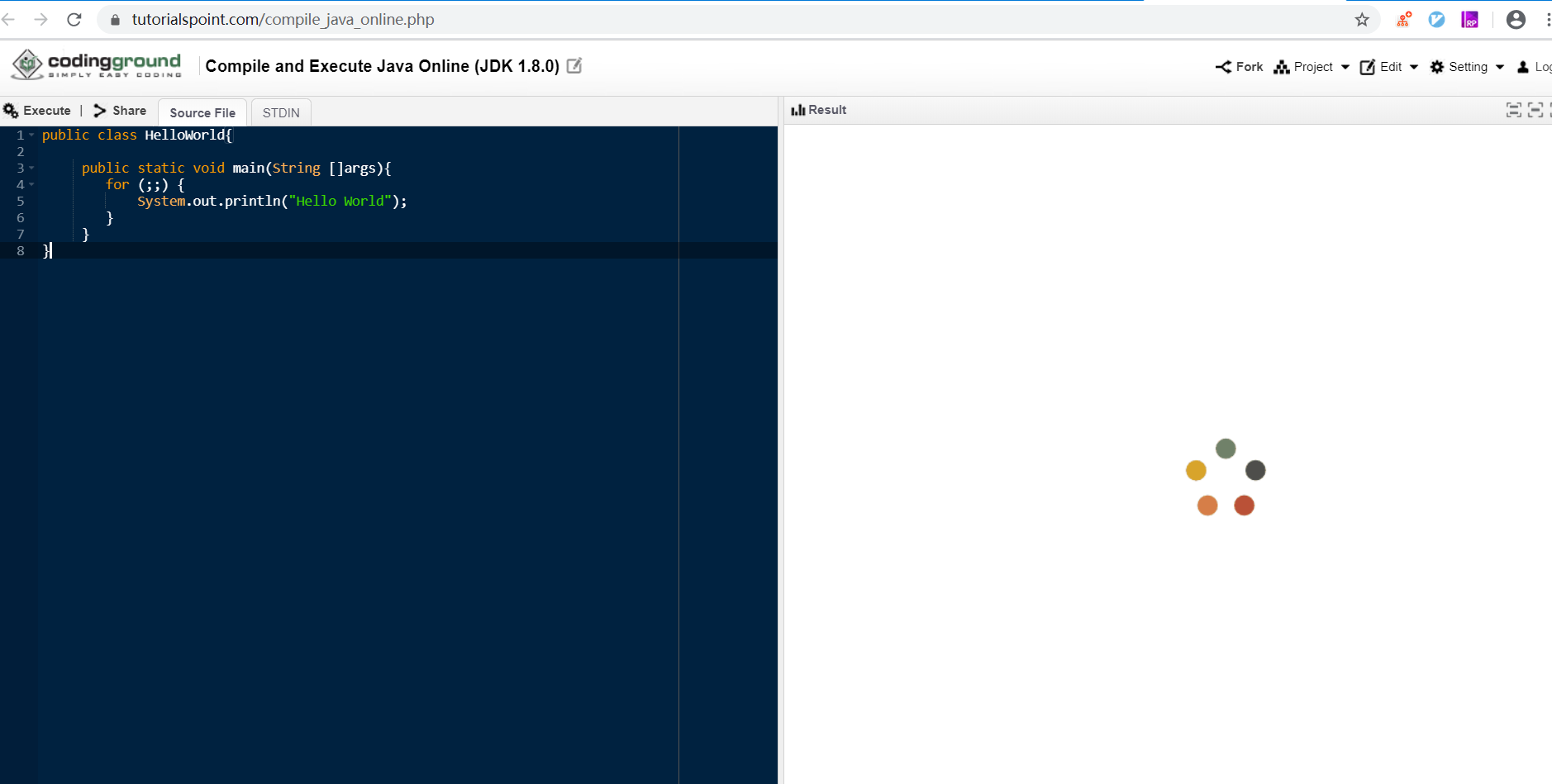
在写 olycode 之前,我去玩了很多别人写的在线 IDE,玩的时候突然升起一股恶趣味,如果我写个死循环它会怎么样呢?结果就是,有些 IDE 还真的被玩坏了的感觉,n 小时过去了,下图右侧的小圈圈还在转……(/溜了)
那这个问题怎么解决呢,之前跟奇凯和贤杰交流了一下,翻翻聊天记录还在,贴出来看看:
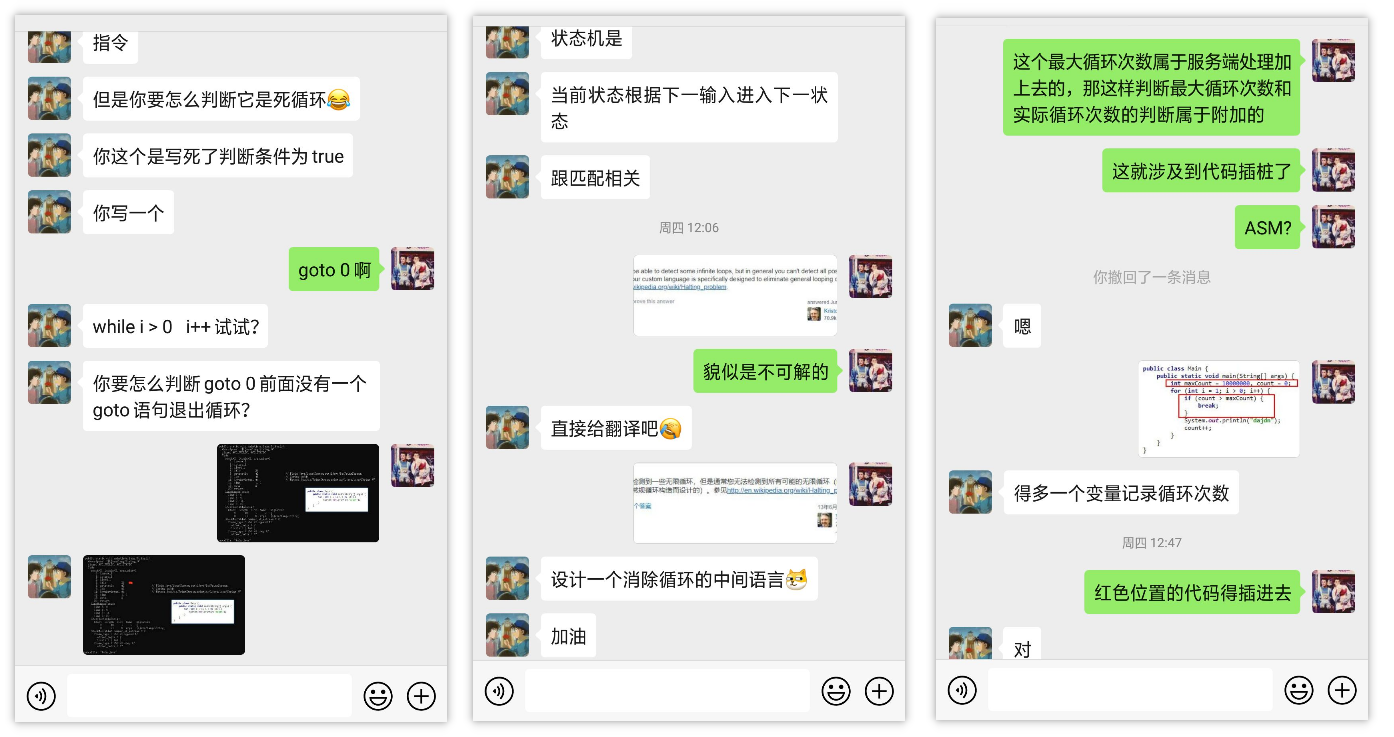
因为 ASM 的 API 实在不好理解(说到底还是懒,看哪天去翻译文档学习一下),所以后面我使用了基于线程池的异步方式执行客户端的代码,再在某个时间阈值后获取执行的结果,如果没拿到,那么就抛出一个超时异常。
后来我又发现了一个很好玩的方式,既然想到使用 ASM,无非只是想要以一种无侵入的对用户透明的方式在源码中插入几条超时判断语句罢了,而在代码执行的过程中需要经历很多过程从而对应很多不同的状态,比如说先经过编译的过程,字符串形式的源码经过词法分析变成 Token 流, Token 流经过语法分析变成抽象语法树,再经过代码生成得到字节码,而 ASM 操纵的是编译得到的字节码,那么如果不在编译后修改源码,其实我们不妨在编译期搞一下事情。
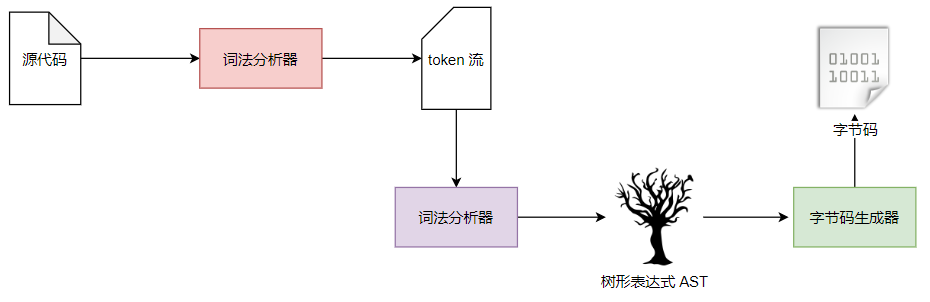
具体在哪一步做呢?由于语法分析得到的抽象语法树去掉了注释和空行等,使得代码处于一种比较简洁的状态,操作起来比较简单,而且巧合的是说到 AST 分析,tools.jar 也提供了相应的 API,下面我们就来看看具体要怎么操作。
Compiler Tree API
compiler Tree API 使用访问者模式访问节点,这个模式的基本思想如下:首先我们拥有一个由许多对象构成的对象结构(比如一棵语法树,其中有很多节点元素),这些对象的类都拥有一个 accept 方法用来接受访问者对象;访问者是一个接口,它拥有一个 visit 方法,这个方法对访问到的对象结构中不同类型的元素作出不同的反应;在对象结构的一次访问过程中,我们遍历整个对象结构,对每一个元素都实施 accept 方法,在每一个元素的 accept 方法中回调访问者的 visit 方法,从而使访问者得以处理对象结构的每一个元素。我们可以针对对象结构设计不同的访问者类来完成不同的操作。按照我的理解,访问者模式实现了数据和操作的分离。
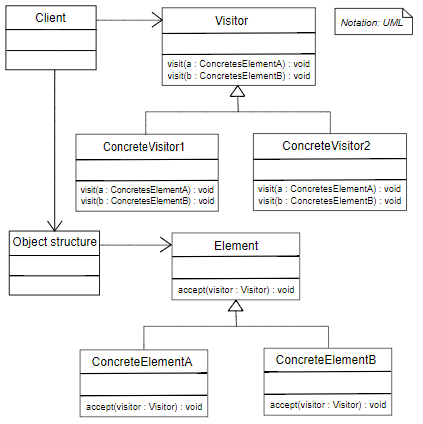
Compiler Tree API 的接口文档在这里,可以看到 AST 相关的类结构,
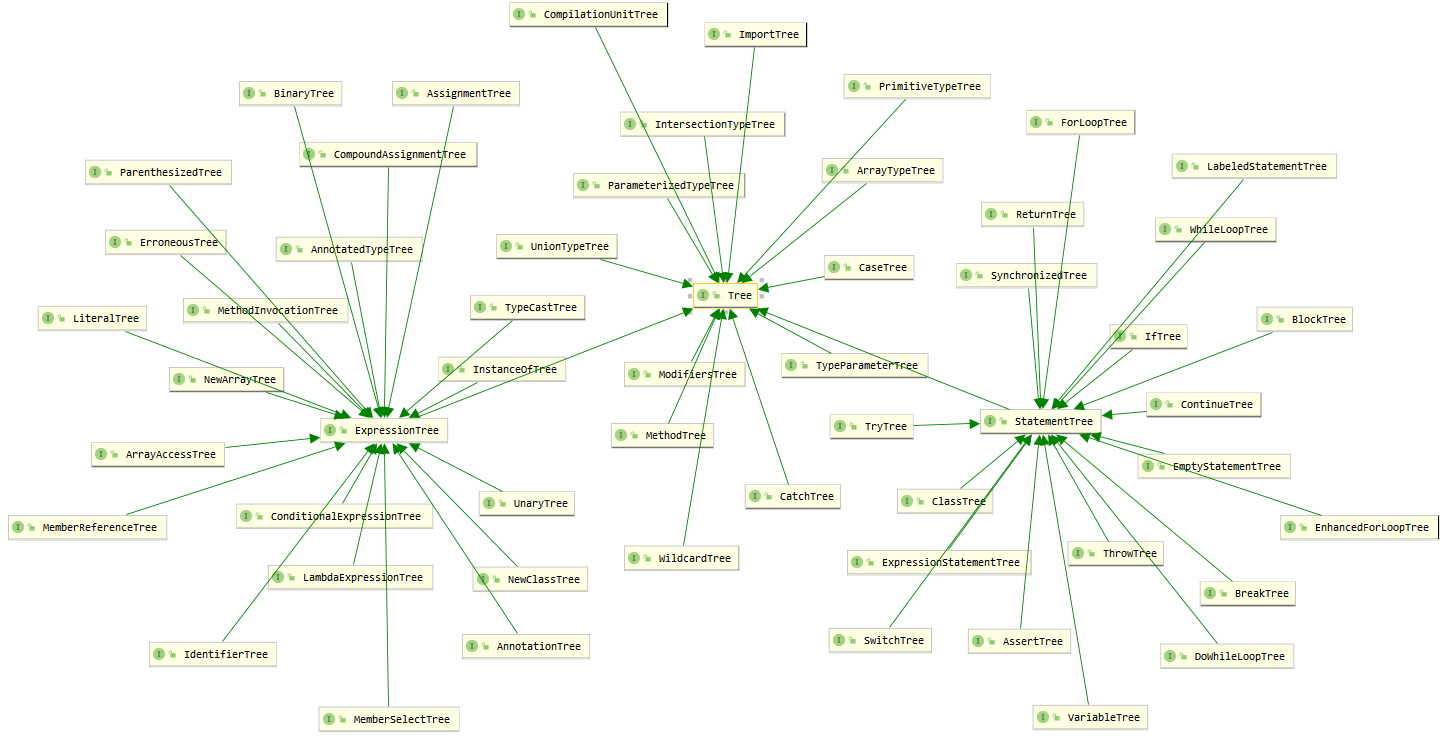
对应的 visitor 接口TreeVisitor与 AST 形成了标准的访问者模式,其中主要的 visitor 有三种:
SimpleTreeVisitor:当访问一个分支节点时默认不会 “往下” 继续遍历它的所有子节点。TreeScanner:默认会遍历所有节点的子节点,在遍历当前节点的同时可以获取到上一个被访问的邻接兄弟节点的访问结果。TreePathScanner:继承自TreeScanner,在遍历当前节点的同时除了可以获取到上一个被访问的邻接兄弟节点的访问结果外,还能获取到父节点的访问结果。

下面我们看看怎么通过 Compiler Tree API 分析及动态操纵 AST,以死循环代码的检测为例:
|
|
Java 中的循环有 4 种,分别是简单的 for 循环、增强 for 循环、while 和 do-while,各自分别对应的节点类型是ForLoopTree、EnhancedForLoopTree、DoWhileLoopTree和WhileLoopTree。通过下面代码见到,我对它们的处理都是一样的,
- 先调用
super.visitXXLoop以确保转换也应用于节点的子节点(嵌套循环)。 - 执行实际的转换,其逻辑封装在
manipulateNode(node)方法中。
|
|
我们再看manipulateNode(node)方法:其中主要经过三个步骤
- 生成时间声明语句节点
- 在本循环之前,挂上起始时间声明
- 在本循环之内,最后一条语句后,挂上超时判断
|
|
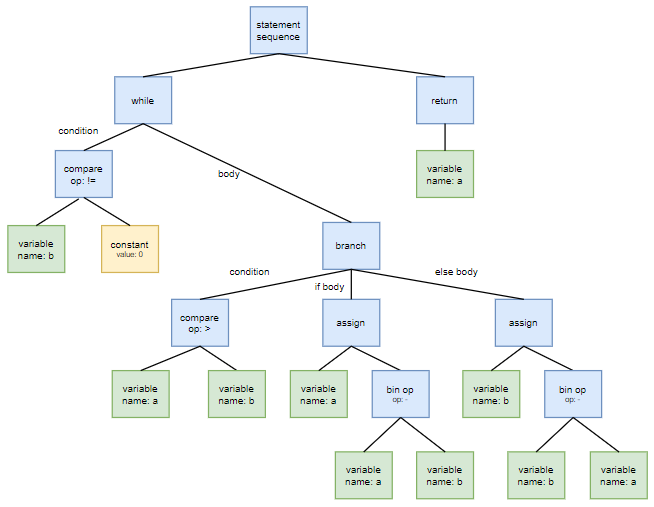
假设有这么一段代码
|
|
则其抽象语法树表示大致如下图所示
经过上述过程后生成的代码如下所示:
|
|
则经过修改的语法树对应如下所示:
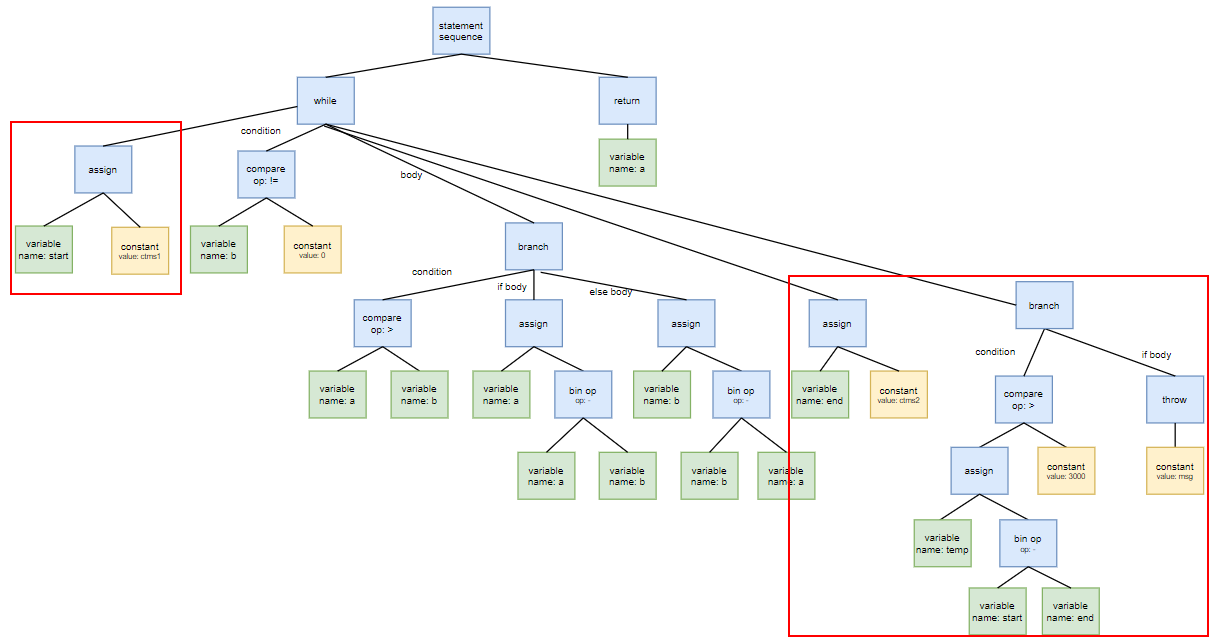
上述操作过程的代码如下所示,其中hookBefore 用于将 toBeInserted 插入到current节点之前,appendAsLastChild 用于将toBeInserted插入到node的最后一个child的位置。

插件化注解处理
有了上面定义的对抽象语法树的访问器之后,我们需要解决另一个问题是,要怎么样才能使得访问器生效呢?答案是使用 jdk1.6 的 Pluggable Annotation Processing 机制(相关 JSR 链接),在编译器获取编译任务的时候设置对应的Processor。
Java 5 中引入了注解,作为在源代码中附加元信息的一种方式,但是注解的作用范围不包括编译期。Java 6 通过 JSR 269 提供可插入注释处理 API,将注解提升到了下一个级别。 JSR 269 使用插件机制扩展了 Java 编译器。使用这个 JSR,现在可以编写可插入到编译过程中的定制注释处理程序。
注解处理按轮进行。在每一轮中,可能会要求处理器处理前一轮生成的源文件或字节码文件中发现的注解子集。所述第一轮加工的输入是插件化注解处理器工作的初始输入,这些初始输入可以看作是一个虚拟的第零轮处理的输出。如果一个处理器被要求在一个给定的轮中进行处理,那么它将被要求在随后的轮中进行处理,包括最后一轮,即使它没有需要处理的注解。
为了编写一个注释处理程序,我们从 AbstractProcessor 派生出子类,并用 SupportedAnnotationTypes 和 SupportedSourceVersion 注释我们的子类。子类必须重写两个方法:
public synchronized void init(ProcessingEnvironment processingEnv)public boolean process(Set annotations, RoundEnvironment roundEnv)
Java 编译器在注释传递期间调用这两个方法。第一个方法被调用一次来初始化插件,后一个方法在每个注释轮中被调用,在所有轮完成后再调用一次,并在每轮中都会用于处理来自前一轮的类型元素上的一组注解类型,并返回处理程序是否声明这些注解。如果返回 true,则声明注解,随后的处理器将不会被要求处理它们;如果返回 false,则没有声明注解,可能会要求后续处理器处理它们。
限于篇幅,不详细展开介绍,下面快速介绍我们定义的注解处理器:
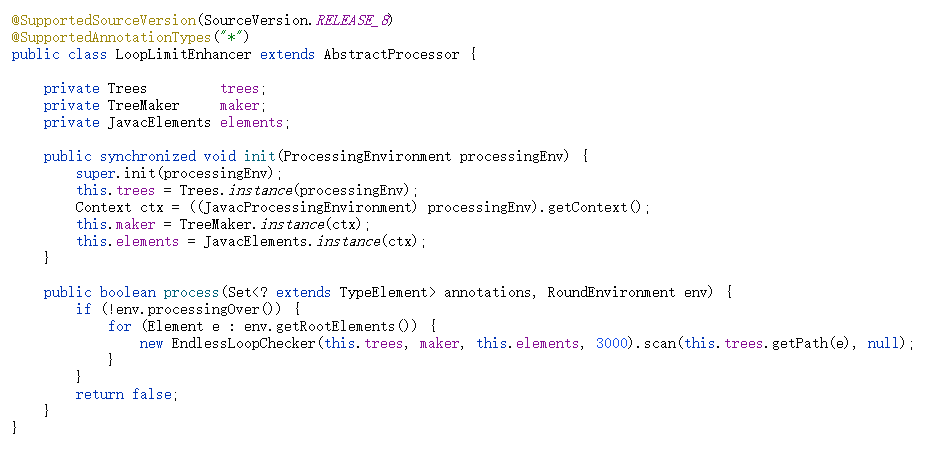
SupportedAnnotationTypes中写为"*",表示作用于所有的类,不管有没有加上注解。SupportedSourceVersion设置了受支持的源代码版本。- 覆盖了
init方法,初始化上下文和相关组件。 - 覆盖了
process方法。对所有类的编译过程都需要调用此方法进行处理。该方法每轮调用一次,最后使用空元素集调用一次。因此,我们使用一个简单的 if 在最后一轮中什么都不做。对于其他轮次,我们使用上面定义的死循环代码检测器EndlessLoopChecker进行处理。该方法返回 true,以便其他处理器继续处理。
在init方法中我们使用处理环境(ProcessingEnvironment)来获取必要的编译器组件。在编译器中,对编译器的每次调用都使用单个处理环境(或上下文,在内部称为上下文)。然后使用上下文来确保每次编译器调用存在每个编译器组件的单一副本。在编译器中,我们只需使用 Component.instance 来获得对组件的引用。我们使用到的组件有:
- Trees:在程序元素和树节点之间架桥。例如,给定一个方法元素,我们可以得到它关联的 AST 树节点。
- TreeMaker:编译器的内部组件,它是创建树节点的工厂。
- JavacElements:用于实例化和存储抽象语法树的元素节点。
最后我们在获取编译任务时设置该处理器,
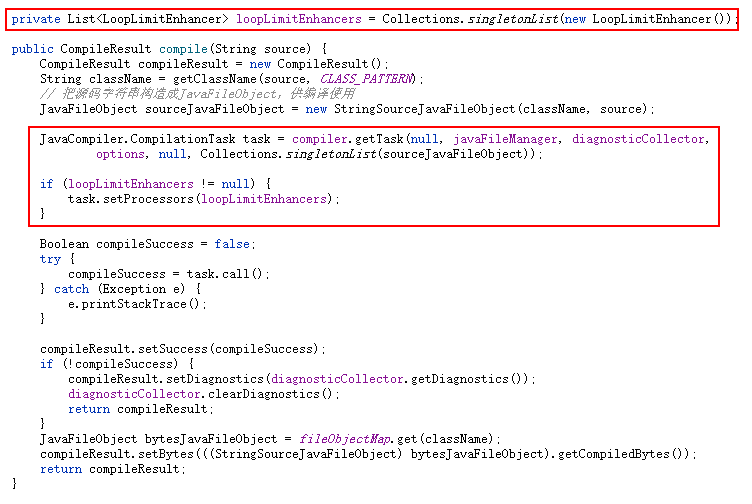
下面我们来运行看看效果,可以看到代码跑了三秒后抛出异常:

总结
本文介绍了 olycode 的实现部分,并展开介绍了相关的 Compiler API 及基于它和类加载机制实现源代码的编译执行,另外为了实现死循环代码的检测,利用 Compiler Tree API 进行抽象语法树分析,再在其基础上,使用 Pluggable Annotation Processing 机制,设置编译器注解处理程序,实现抽象语法树循环元素节点的分析和动态操纵,通过植入超时判断语句节点,生成新的目标代码,实现死循环代码超时异常处理。
上述实例代码已经上传到了Github,感兴趣的朋友可以点传送门。
这里再简单扩展一下,如果你进行过 Java 开发,那么很可能听说过 lombok,其实它的设计思想就是基于类似上面所述的语法树分析和操纵,并通过插件化的注解处理器实现编译器动态代码生成。感兴趣可以看看这个 DIY 的 乞丐版lombok,限于篇幅,以后有机会再抽空详述。
以上,希望对你有帮助,欢迎在评论区给我留言。