很久之前我写了这么一个并发异步的工具方法,传入的 suppliers 是具体的业务方法函数引用,考虑这个一个业务场景,我们需要去数据库统计某个表最近一个月在某个条件下的数量,那么为了提高响应效率,可以通过按天切分日期,然后组装成相应的 supplier,再通过多线程异步处理,最后统一收集完结果返回。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
public static <R> Collection<R> supplyAsyncWithExpDeal(Collection<Supplier<R>> suppliers,
boolean distinct, Executor executor,
Function<Throwable, R> expHandler) {
Collection<R> res = distinct ? new HashSet<>() : new ArrayList<>();
if (CollectionUtils.isNotEmpty(suppliers) && Objects.nonNull(executor)) {
log.info("FutureUtils.supplyAsync ==> size of suppliers: {}", suppliers.size());
// wait for all tasks to finish
CompletableFuture.allOf(
suppliers.stream().filter(Objects::nonNull).map(supplier ->
CompletableFuture.supplyAsync(supplier, executor).thenApply(r -> {
if (Objects.nonNull(r)) {
// concurrent contending point
res.add(r);
}
return r;
}).exceptionally(throwable -> {
R r = expHandler.apply(throwable);
res.add(r);
return r;
}
)
).toArray(CompletableFuture[]::new)).join();
}
return res;
}
|
最近有同事提醒我,收集结果的地方存在潜在的并发问题,原来我的考虑是在一个方法里创建的变量是在栈里面的,所以多线程并发时,创建的 res 对象是不一样的,所以没有线程安全问题,但是 CompletableFuture 处理是基于线程池的,即后面在方法内部再分发任务到 executor 中的工作线程(我没睡醒),由于此处使用的是线程不安全的集合类,所以 add 方法存在线程安全问题,解决方案是将问题行替换为:
1
|
Collection<R> res = distinct ? new ConcurrentHashSet<>() : new CopyOnWriteArrayList<>();
|
其中因为 JDK 没有提供 ConcurrentHashSet 实现,此处的 ConcurrentHashSet 来自 hutool 工具包。
然而改完之后,合代码到生产环境时,我还是有点心虚,因为我不确定为什么这样改就能高枕无忧了,先不管 List,在千千万万的博客文章中,人人都说 HashMap、HashSet、ArrayList 等等不是线程安全的,要使用相应的 JUC 包下的工具类。周遭那些整天大喊 “进大厂必背的面试题” 中必然出现的一点是,被问到 “HashMap 和 ConcurrentHashMao 的区别” 时一定要答 “HashMap 不是线程安全的,ConcurrentHashMap 是线程安全的”,那么,先不说 ConcurrentHashMap 是怎么保证线程安全的,HashMap 在多线程并发的场景下会有什么问题呢?有人说可能会出现死循环,可能会导致 CPU 100%,可能会导致丢数据,那么真的是那样吗?如果是,又是怎么出现的呢?所谓实践出真知,我们不妨自己试着一一验证,而不是人云亦云。
一、环境准备
为了模拟多线程并发的场景,我需要在源码中进行判断和控制,所以我需要能够随意地修改 HashMap 的源码,但是 JDK 是只读的,那么怎么办呢?简单,把源码及相关的依赖复制出来就行,因为人们都说 JDK 8 的 HashMap 对大部分问题进行了修复,尽管它还不是线程安全的。那我们就一步步来,先看看 1.7 版本中会有什么问题,所以我搞了个 jdk-7u80 中的哈希表源码抠了出来,并进行了修改,它和一些测试代码组成的完整的工程可见 这里。
二、HashMap 的运作
JDK 1.7 中的 HashMap 采用数组作为哈希表,使用键值对节点头插成链的拉链法解决哈希冲突,当整个 HashMap 中的键值对节点超过一定阈值时,就会进行扩容,扩容的基本运作过程是,新建一个原哈希表数组双倍大小的新数组,然后(可选地)重新计算哈希值,再根据新的哈希值将节点复制到新的哈希表中,当然冲突链中的数据也通过头插法进行重新排布。
对于 put 方法,主要思路是:计算哈希值得到索引,判断是否发生哈希冲突,是则遍历链,如果能找到 key 对应的值,则进行更新,否则进行插入。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
// 如果 key 已经存在,则更新 value,并返回旧值
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
// 如果 key不存在,则插入新的元素
addEntry(hash, key, value, i);
return null;
}
|
对于插入键值对,需要检查此时(不算上将要插入的节点)的节点数是否超过阈值,是则先进行扩容,再将新节点插到新的哈希表中。
1
2
3
4
5
6
7
8
|
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
|
对于扩容,先计算出新的数组的长度(原表长度的两倍)并创建新数组,然后将数据从原数组搬运过去。
1
2
3
4
5
6
7
8
9
10
|
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
...
Entry[] newTable = new Entry[newCapacity];
...
transfer(newTable, rehash);
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
|
对于搬运数据,需要遍历原数组及冲突链,进行重新哈希(如果需要的话)得到新的下标,然后进行搬运,一样地使用头插法排布节点。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
int cnt = 0;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
|
三、场景模拟
很多人说多线程环境下哈希表的扩容操作并发时,会出现节点成环的情况,从而在 get 某个节点的时候出现死循环,但他们没有给出实际的 debug 过程,我们不妨来尝试模拟这种场景。
HashMap 的实时容量记为 size,扩容阈值为 threshold,如果 size >= threshold,则进行扩容,其中 threshold = capacity * loadFactor,capacity 为用户指定的表大小,如果不指定则默认为 16,loadFactor 可理解为一个比例,即达到百分之多少进行扩容,默认地 loadFactor = 0.8,为了便于测试,我们将 capacity 设为 4,loadFactor 设为 1.0,并进行数据初始化。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
final HashMap<CustomKey, String> map = new HashMap<>(4, 1);
final CustomKey k1 = new CustomKey(1, "a");
CustomKey k2 = new CustomKey(1, "b");
CustomKey k3 = new CustomKey(1, "c");
final CustomKey k4 = new CustomKey(1, "d");
final CustomKey k5 = new CustomKey(1, "e");
map.put(k1, "aa");
map.put(k2, "bb");
map.put(k3, "cc");
map.put(k4, "dd");
final HashMap.Entry<CustomKey, String>[] table = map.table;
for (HashMap.Entry<CustomKey, String> customKeyStringEntry : table) {
System.out.println(customKeyStringEntry);
}
|
其中,CustomKey 是我自定义的一个类,作为键值对的键对象。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
public class CustomKey {
private int hashCode;
private String uid;
// constructors...
@Override
public int hashCode() {
return hashCode;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
CustomKey customKey = (CustomKey) o;
return Objects.equals(uid, customKey.uid);
}
@Override
public String toString() {
return uid;
}
}
|
不得不提的是,HashMap 的哈希函数如下所示,很显然这个算法是跟对象的 hashCode 有关的,所以为了模拟哈希冲突,我需要能够控制每个测试对象的 hashCode,所以将之作为类的属性之一。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
|
另外,结合前面的 put 函数,如果 e.hash == hash && ((k = e.key) == key || key.equals(k)),则认为该键对象已经存在,而不是认为发生哈希冲突,所以我还需够重写 equals 方法,
因为默认地,所有对象的 equals 都继承自 Object 中的 equals 方法(比对堆地址),所以,如果一个类重写了 equals 方法,通过类的属性组合而不是地址作为对象的唯一性特征(即如果两个对象的各项特性一样,那么我们认为它们是 equals 的)时,那么新增元素会按照各个属性维度判断键值对是否已经存在,从而不往其中插入键一样的键值对,我们重写了 equals,那么往往还需要重写 hashCode 方法,结合对象的各个属性来计算 hashCode,因为前面的 e.hash == hash && ((k = e.key) == key || key.equals(k)) 判断才会认为两个属性相同的对象可认为同一对象。总有人说,如果重写了类的 equals 方法,一定要重写 hashCode 方法,但是倘若这个类的对象不作为哈希表的键,那么这个所谓的 “准测” 看起来让人觉得十二分莫名其妙。
1
2
3
|
public boolean equals(Object obj) {
return (this == obj);
}
|
按照上面的理解,我们的 hashCode 方法应该由对象的各个属性决定的,但是为了模拟哈希冲突,我故意为多个对象设置了一样的 hashCode,让它们排成一条链表。为了便于观察,我重写了 HashMap.Entry 的 toString 方法,对冲突链进行格式化。
1
2
3
4
5
6
7
8
9
|
@Override
public String toString() {
StringBuilder res = new StringBuilder("{" + key + ", " + value + ", " + hash + "}");
if (next != null) {
res.append(" -> ");
res.append(next.toString());
}
return res.toString();
}
|
看下上面我们构建的哈希表输出:
1
2
3
4
|
null
{d, dd, 1} -> {c, cc, 1} -> {b, bb, 1} -> {a, aa, 1}
null
null
|
现在整个哈希表的数据状态大致如下所示:
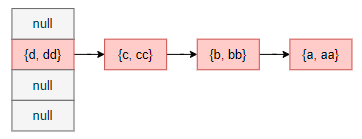
由于扩容阈值是 4,所以当我们再尝试往其中添加一个 hash 到 1 号桶下标的键值对 {e, ee} 的时候,将会触发扩容,倘若正巧有多个线程在扩容操作中并发,那么会发生什么呢?我们假设现在有两条线程并发插入一个键值对到同一位置,触发扩容。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
ThreadUtils.sleep(1);
map.put(k5, "ee");
}
});
t1.setName("T1");
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
map.put(k5, "ee");
}
});
t2.setName("T2");
t2.start();
t1.start();
|
四、分析与测试
对于上面的场景,因为线程 T1 启动后即进行了一秒休眠,记其后的某个 t1 时间点,线程 T2 先进入扩容方法,它创建了一个新的数组,并尝试将旧数组中的数据搬运到新数组中,此时其时间片用完,上下文切换到线程 T1 上。
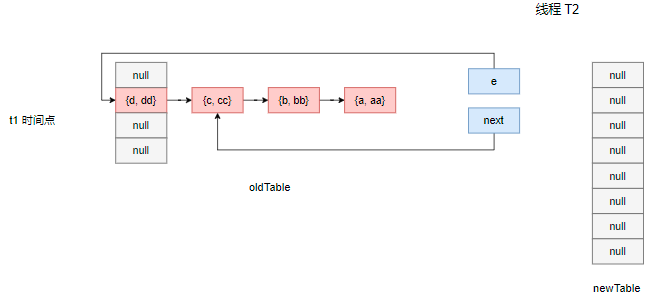
为了模拟线程 T2 用完时间片,我们在它遍历 {d, dd} 这个节点的时候让它陷入休眠,注意此时它的栈空间中持有了 e 和 next 句柄指向。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
int cnt = 0;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
// 线程 2 陷入此处,e = dd,next = cc
if (cnt == 0 && "T2".equals(Thread.currentThread().getName()) && e.hash == 1) {
System.out.println("T2进入休眠");
ThreadUtils.sleep(2);
}
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
|
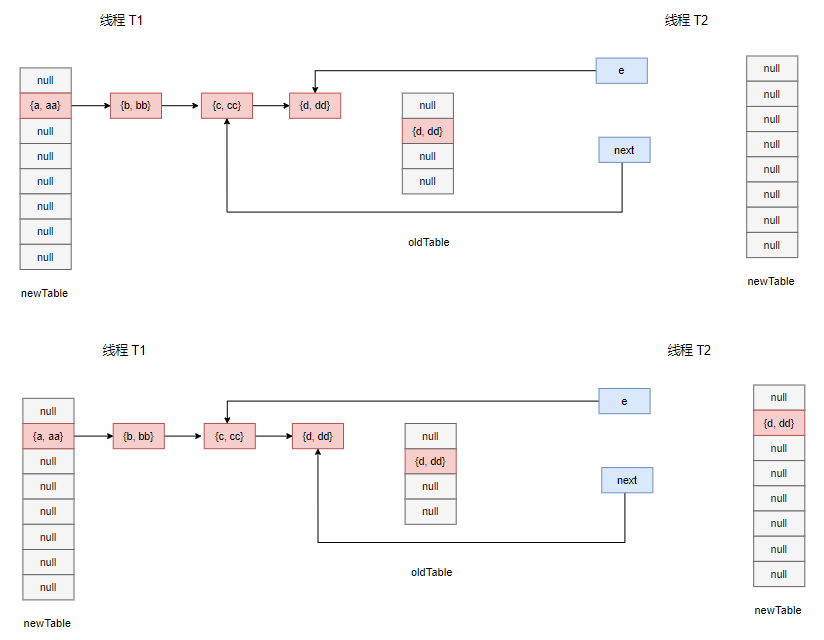
接下来在 t2 时间段内,线程 T1 尝试放入 {e, ee},同样地也会触发扩容,在 resize 方法中创建自己的新数组,然后进行数据搬运,让我们来看看数据搬运的过程:
在遍历过程中,首先 e 和 next 分别指向 {d, dd} 和 {c, cc} 节点,然后 {d, dd} 和 {c, cc} 间的指针断开,{d, dd} 被拷贝到了新数组上,e 指针向前移动。
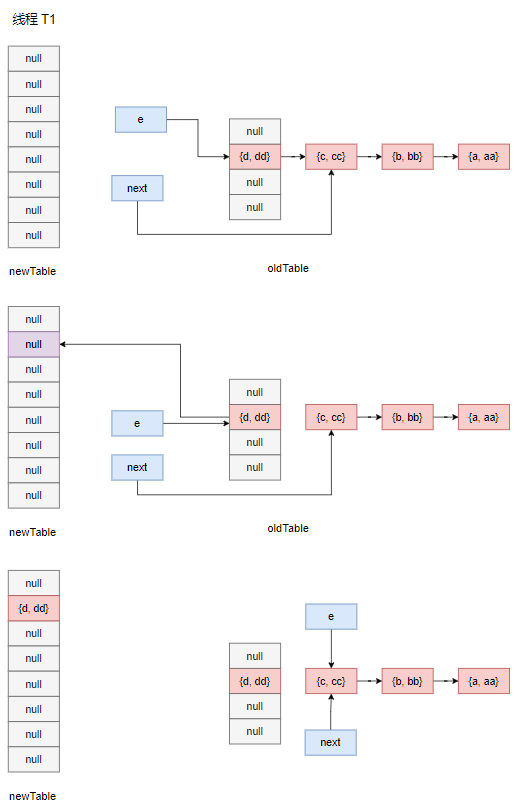
经过多轮迭代,最后两个数组的情况如下所示:
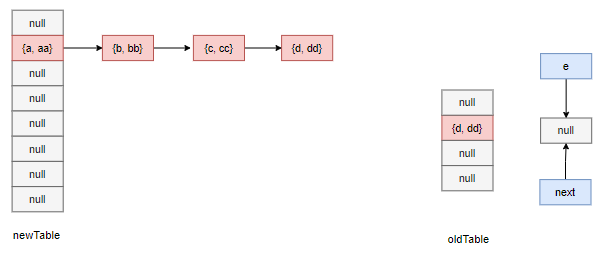
假设在此时开始的 t3 时间内,线程 T1 失去时间片,线程 T2 苏醒并继续它未完成的任务,我们在 table 赋值的地方对线程 T1 进行休眠处理:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
if ("T1".equals(Thread.currentThread().getName())) {
System.out.println("T1进入休眠");
ThreadUtils.sleep(6);
}
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
|
前面我们提到,线程 T2 已经持有了自己 e 和 next 句柄,分别指向 {d, dd} 和 {c, cc} 节点,但是由于线程 T1 在数据搬运过程中颠覆了整条链的指针指向情况,尽管数据搬运是一个拷贝过程,但是拷贝也分为深拷贝和浅拷贝,此处的拷贝属于浅拷贝!所以此时对于线程 T2 来说,它看到的情况是这样的:
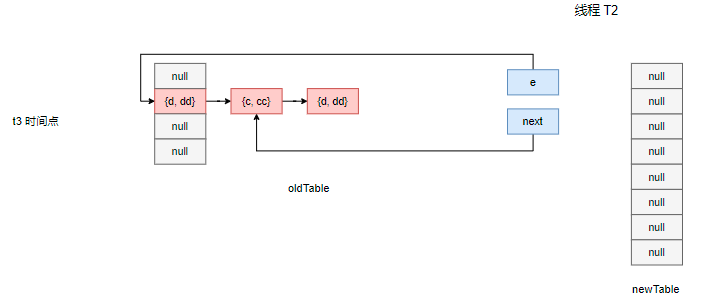
然后它尝试进行搬运,{d, dd} 被浅拷贝到新数组的下标为 1 的桶口,e 指向 next 记录的 {c, cc} 节点,而在下一个循环的开始时,next 指向原 {c, cc} 的下一个节点,因为是引用指向,所以 next 指向了线程 T1 中的新数组中的冲突链表记录的 {d, dd} 节点。
于是 {c, cc} 节点理所当然地被头插到 1 号桶口,其 next 指针指向了 {d, dd} 节点,接下来,e 指向了原局部变量 next 指向的 {d, dd},下一次迭代进来会尝试将 {d, dd} 头插到 {c, cc} 前面,而 {c, cc} 的 next 指针已经指向了 {d, dd},从而出现了循环引用的情况,试想如果此时线程 T2 调用 get 方法,那么将会触发死循环。
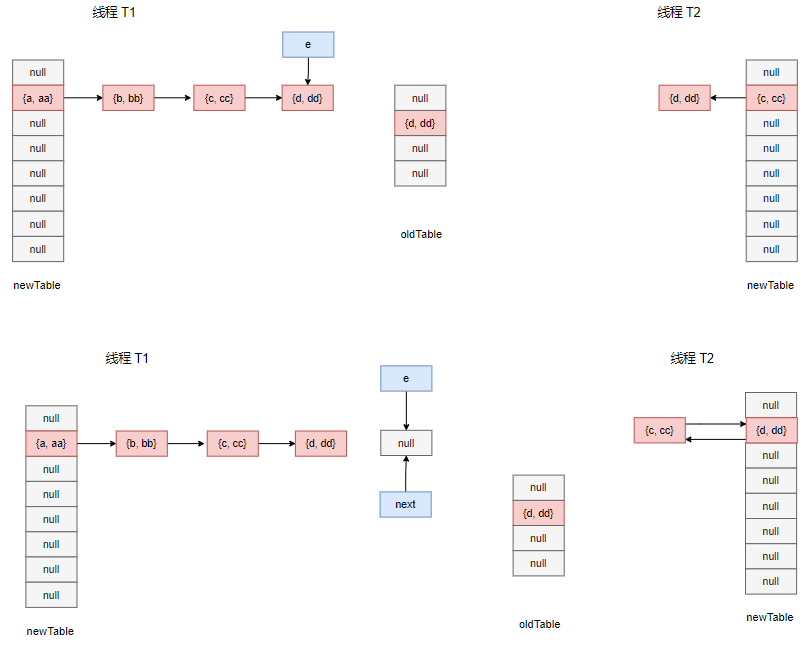
我们尝试在线程 T2 中调用 get 方法进行测试:
1
2
3
4
5
6
7
|
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
map.put(k5, "ee");
map.get(k1);
}
});
|
为了结果直观化,我尝试将运行过程做成了 gif,看着还挺好玩。结果也很明显,的确出现了死循环。
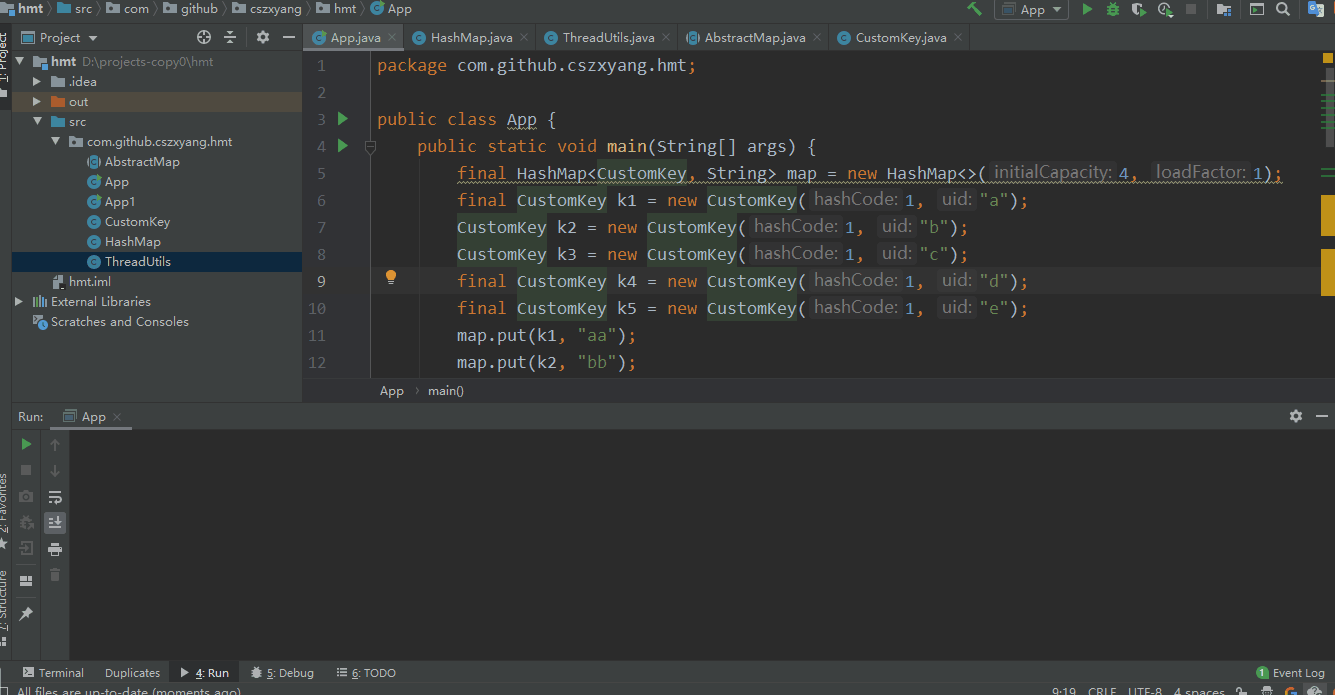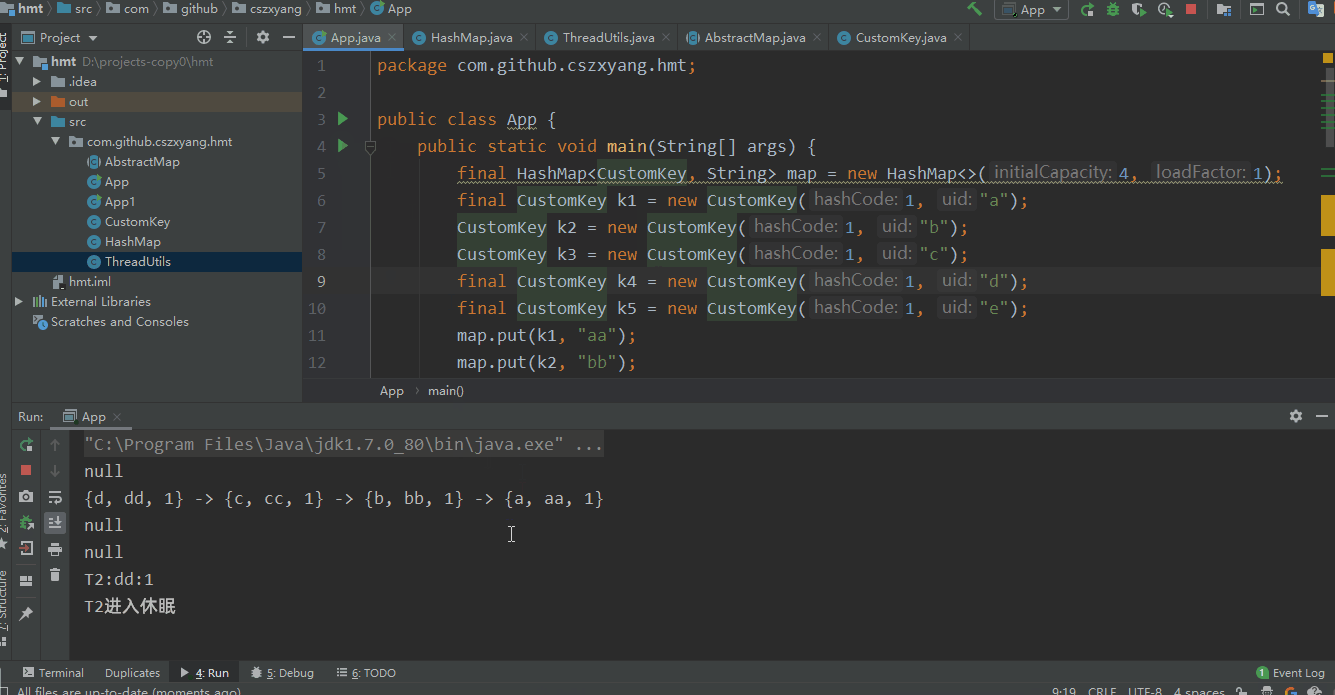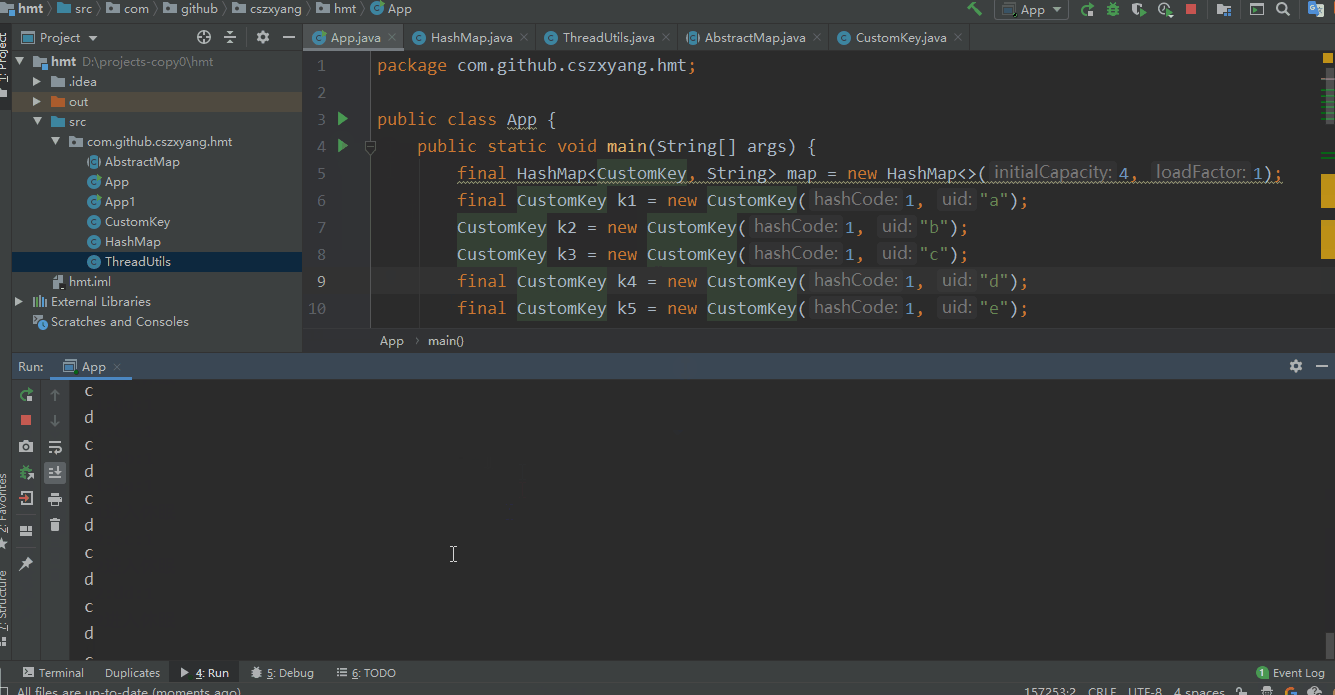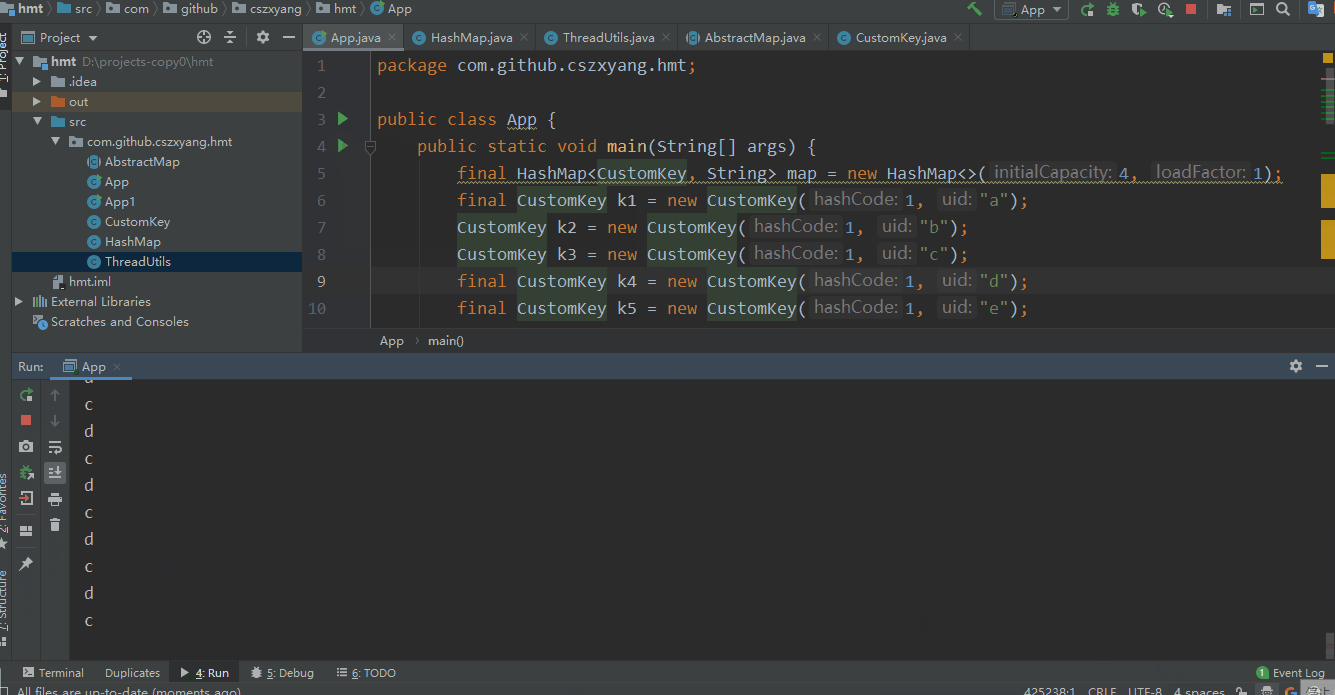
与此同时,我们打开任务管理器查看 CPU 运行情况,可以看到 CPU 利用率已经去到了 100%,把程序停掉后恢复正常。
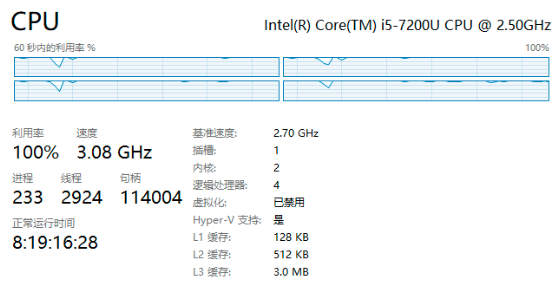
如果线上环境出现 CPU 利用飙升的情况,对于 Windows服务器,通过 tasklist 命令拿到 JVM 的 PID,

然后使用 jstack 查看线程运行情况,然后定位到具体的代码位置。
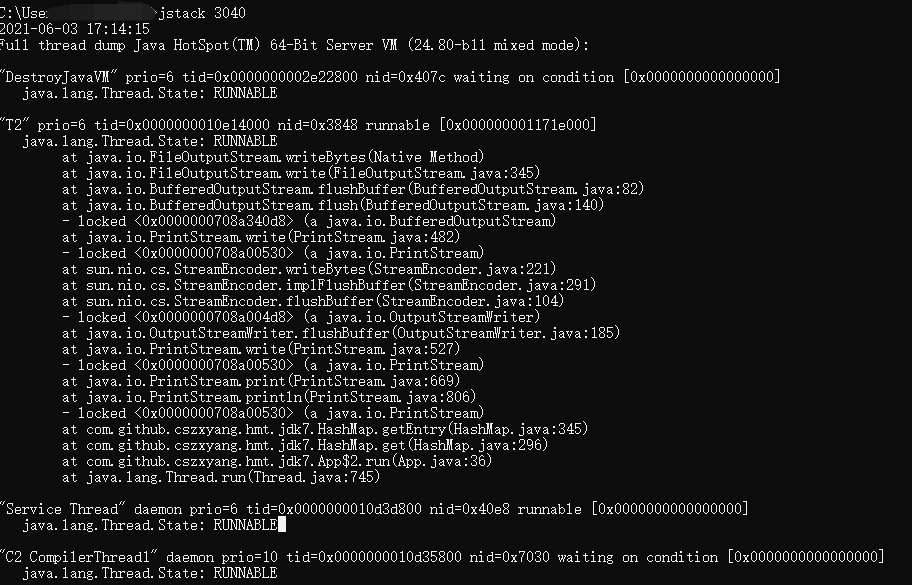
对于 Linux 服务器,可以使用 top -p 265 -H 命令查看 CPU 占用率高的进程,如果是 JVM 进程,拿到其 10 进制的 pid,然后通过 printf "%x" xx 转成十六进制,再使用 jstack 查看线程运行状况。
试想如果极端一点,某个系统的并发量极高,同一时刻有 100 条像 T2 这样的线程在成环的冲突链表上调用 get 方法,那么服务的可用性将会受到极大的威胁。
1
2
3
4
5
6
7
8
9
10
11
|
for (int i = 2; i < 102; i++) {
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
map.put(k5, "ee");
map.get(k1);
}
});
t2.setName("T" + i);
t2.start();
}
|
五、总结
JDK 1.7 版本的 HashMap 由于没有做同步控制(事实上,它的设计初衷本身不是用于并发场景),所以需要避免在多线程环境下使用它来存储数据,因为在多线程并发扩容的时候,由于采用头插法及浅拷贝,会导致数据丢失及节点循环引用的情况,从而在后续调用 get 方法时触发死循环。