JDK 源码 - AbstractQueuedSynchronizer
前段时间线上遇到 OOM 问题,定位到的原因是线程池创建线程的个数过多,导致内存不够用;为此好奇去看了眼线程池的源码,发现线程池会在调度任务执行时才会创建实际的线程对象,但是再往下看时遇到了不懂的东西,比如 AbstractQueuedSynchronizer ,没办法只好先把基础的组件搞明白。
一、简介
AbstractQueuedSynchronizer 是一个抽象类,从字面上看,它是一个 Synchronizer,即一个线程同步器,按我理解是一个实现并发同步控制(如锁、异步转同步工具)的标准和规范, JDK 并发包 java.util.concurrent 下的很多组件都是基于它实现的,如 ReentrantLock、CountDownLatch、ReentrantReadWriteLock、Semaphore 等;另外它还被 Queued 修饰,也就是它是带有队列辅助控制的。
AbstractQueuedSynchronizer 采用队列的方式缓存获取不到临界资源的线程,这个队列的设计参考了 CLH,保留了 CLH 释放资源时通知后继节点的思想,但是在自旋方面做了优化,关于 CLH 的内容在此不展开讲述。纵观 AbstractQueuedSynchronizer 源码,其中主要特点是使用了 CAS、自旋、park/unpark 、模板方法设计模式等技术或设计模式,当然还有很多巧妙的算法实现。
1. CAS
CAS 全称是 Compare And Swap,即 “比较现在的值是否符合预期,是则将之设置成想要的值”,因为在并发环境下,某个线程在比较与交换期间可能有其他线程对该内存进行了操作,所以 CAS 必须是一个原子性的操作,这样才能保证新值的设置是基于前一个最新的数据版本计算而来的。
一般来说,CAS 的返回值是被 swap 出来的旧值,有些地方返回一个 boolean 值,表示该操作是否能设置成功,如果在 CAS 期间,有其他线程修改了给定内存的数据,那么返回失败,这种只关心是否设值成功的方法,而不关心被替换的旧值的方法往往称为 Compare And Set。
JDK 通过 Unsafe 类提供了 CAS 接口,至于 Unsafe 怎么实现 CAS 此处不展开介绍。
2. 线程可见的同步状态
前面提到如果在一个线程 t0 在 CAS 期间可能有另一个线程 t1 修改了内存的数据,那么 t1 这个修改的动作需要让 t0 有所感知,为此相应的数据变量需要使用 volatile 修饰,以使得它的变化对各线程实时可见。
所以AbstractQueuedSynchronizer中设置了一个 private volatile int state; 字段,抽象而言,它是某种临界资源,可以将之简单理解成锁,由于我们这篇文章主要讲述 AbstractQueuedSynchronizer ,不涉及锁这个概念,所以我称这个字段为 同步状态。
3. park 与 unpark
如果一个线程去获取同步状态失败,有一个处理方式是让它不停地自旋,也就是写个死循环,不获取到锁不罢休,但是这样太耗费 CPU 资源了,所以不妨让获取不到锁的线程先阻塞,如果同步状态释放了而它又有机会获取到的话就唤醒它去尝试获取。
为了实现释放时间片,或许可以考虑的方式有:
- 让获取同步状态失败的线程
sleep,但是线程休眠的时间难以确定; - 使用 wait 让线程阻塞,但是据说 wait 与 notify 设计用于线程通信所以不合适(待学习)
所以作者使用了 LockSupport 中的 park/unpark 方法实现线程的阻塞与唤醒。
4. 模板方法设计模式
作为一个抽象类,一个实现同步控制的标准,很正常地,AbstractQueuedSynchronizer 中会对某些操作抽象化,让实现 AbstractQueuedSynchronizer 标准的子类去实现这些方法,但 AbstractQueuedSynchronizer 不仅仅是提供接口,它需要有自己的一套运作基础,所以在 AbstractQueuedSynchronizer 源码中看到模板方法设计模式并不需要感到惊讶。
4.1. 模板方法
AbstractQueuedSynchronizer 支持独占模式和共享模式,对于同步状态的获取和释放,都分别定义了相应的模板方法,模板方法中再根据子类的钩子函数执行情况决定后面的操作。
|
|
4.2. 钩子函数
由于 AbstractQueuedSynchronizer 只是制定了获取和释放前后的流程,至于获取和释放同步状态本身的操作则是需要具体的子类去实现,因为它只是标准的制定者。所以如果子类没有重写下面这些钩子函数,将会抛出异常,因为 AbstractQueuedSynchronizer 的运作需要依赖回调钩子函数的执行情况。
|
|
二、源码分析
从持有同步状态的线程数来看,AbstractQueuedSynchronizer 支持独占和共享模式,独占模式下只能有一个线程持有同步状态,在此期间,其他没有获取到同步状态的线程只能等待;共享模式下则支持多个线程同时持有同步状态。
所谓的获取同步状态其实就是某个线程 t 通过 CAS 操作将 state 字段从 0 改成 1,如果改成功,那么就称该线程持有了该同步状态,在独占模式下,其他线程只能等待线程 t 释放该同步状态才有机会获取到该同步状态,而所谓的释放同步状态,其实就是将 state 字段从 1 改成 0。
对于独占模式释放同步状态不需要 CAS 操作,因为任一时刻只有一个线程持有同步状态,即任一时刻只有一个线程进行释放同步状态的操作,不存在多线程并发。
下面我们介绍独占模式下的获取与释放同步状态的过程。
1. 独占模式
独占模式下,任何时刻只允许有一个线程持有同步状态,所以,state 状态一般不是 0 就是 1,但是如果是允许同一个线程重入,也就是一个线程多次获取到同步状态,那么 state 逐次就会累加。为了实现独占,设置了 exclusiveOwnerThread 指针,指向当前时刻获取到同步状态的线程。
1.1 获取同步状态
AbstractQueuedSynchronizer 独占模式下获取同步状态的操作在方法 acquire 中,从上文我们知道 acquire 是一个模板方法,它会回调子类的狗子函数 tryAcquire,如果子类不重写 tryAcquire 则默认抛出异常,至于子类怎么实现 tryAcquire 方法本文不关心,我们只关心它的返回值,返回 true 说明获取同步状态成功,否则代表获取失败。
acquire 方法利用了与运算符断路的思想,即在一个判断链中,如果前一个判断不通过,那么便不会再进行后续的判断,换言之,只有前一个判断通过才会继续下一个判断。所以如果 tryAcquire 返回 false,说明获取同步状态失败,由于对 tryAcquire 返回值取非,所以会执行后续的 acquireQueued(addWaiter(Node.EXCLUSIVE), arg) 操作,其实也就是说如果获取同步状态成功,那么方法就差不多结束了,否则需要将线程入队,我们再看入队的操作。
|
|
首先进行的是 addWaiter(Node.EXCLUSIVE) 操作,大致分为以下步骤:
- 创建一个 Node 节点 node,其中的 thread 字段存储当前线程。
- 如果队列已经初始化,采用快速尾插法将 node 插到队列的最后,由于尾插存在多线程并发可能,所以使用
compareAndSetTail,即CAS操作。 - 如果队列还没初始化,那么调用
enq方法。
|
|
我们再看 enq(node) 方法,其中是一个死循环,实际上这个死循环只会迭代两次便结束,第一次迭代时,队列必然没有初始化,那么就会 创建一个 Node 节点作为哨兵,注意哨兵中的 thread 引用不指向任何线程对象,由于在队列未初始化的时候也可能有多个线程来获取同步状态然后竞相创建哨兵,所以这里也使用了基于 CAS 的 compareAndSetHead 方法进行队头的设置;此后进行第二次迭代,由于队列已经初始化,所以只需将 node 节点 CAS 地插到哨兵的尾部即可,死循环结束。
我们看到第二次迭代的操作跟 addWaiter 方法中的 if 判断中操作是一致的,这是由于初始化队列的操作只需进行一次,后续都是直接尾插即可,这样就能理解为什么作者在 addWaiter 方法里写的注释 Try the fast path of enq 了。
|
|
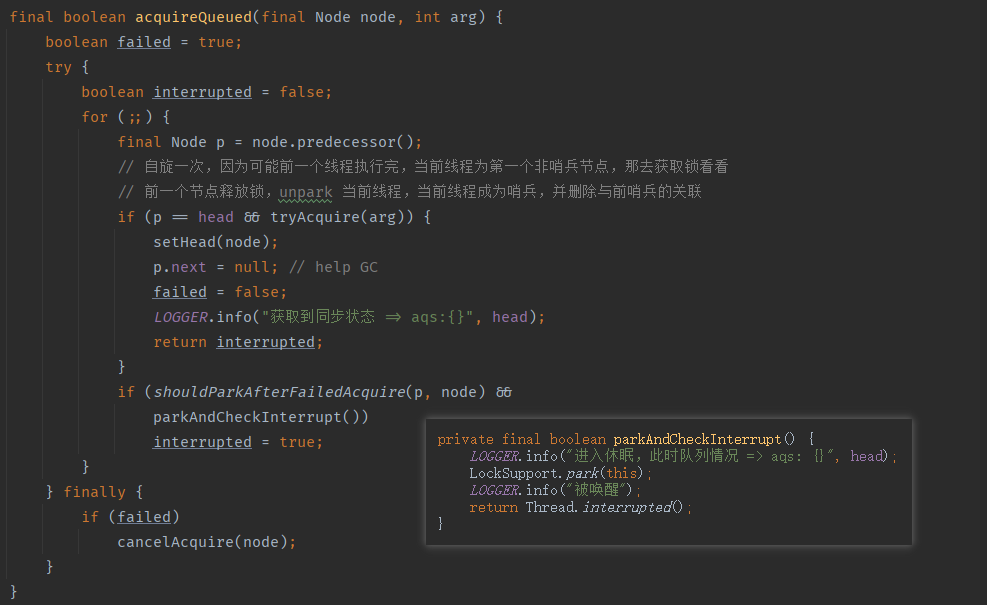
再回到 acquireQueued(addWaiter(Node.EXCLUSIVE), arg) 操作,addWaiter 方法返回的是当前线程的节点,然后传进 acquireQueued 方法。acquireQueued 方法中主要做的事情包括:
- 自旋,判断是否可以获取同步状态。
- 如果获取同步状态失败,判断是否需要 park 阻塞,如果要则进行阻塞。
- 注意线程 park 了之后会阻塞在
parkAndCheckInterrupt方法中,如果某个时刻被唤醒,则会继续尝试获取同步状态,获取不到则又会阻塞,如此循环,直到获取成功为止。
|
|
看到上面的代码需要讲一些细节的地方,首先为什么每次自旋 tryAcquire 获取同步状态时要判断当前节点的前一个节点是否是头节点呢?即 p == head,因为 AbstractQueuedSynchronizer 释放同步状态时,会唤醒靠近队列哨兵的第一个非取消节点,也就是说这个节点具有获取锁的优先权,从这点来看,有点公平锁的意味,但其实 CLH 就是这样的,一个线程释放资源后会唤醒直接后继节点。
如果线程自旋能够获取到同步状态,那么这个线程所在节点中的 thread 指针将被置空并成为新的哨兵节点,原哨兵节点会被删除引用关系等待垃圾回收器回收;而如果线程还是获取不到同步状态,那么会先进入 shouldParkAfterFailedAcquire 判断当前节点是否能被阻塞,此处涉及 Node 节点的 waitStatus 这个变量,它的取值范围在以下几个常量中:
- CANCELLED:代表该节点存储的线程取消排队,那么这样的节点是需要清理的;
- SIGNAL:代表当前节点的后继节点需要被唤醒,因为阻塞的线程已经让出了 CPU,只能等待外界将之唤醒,所以线程休眠前,会在其前继节点中打上标记,告诉它当前线程让出时间片,而不是一直在自旋,因为这样会很浪费 CPU 资源,以后如果它(前继节点)释放了同步状态,需要向当前线程发出唤醒信号。
- CONDITION:待研究。
- PROPAGATE:与资源锁有关。
|
|
有了这样的背景,我们再看 shouldParkAfterFailedAcquire 方法,大致可分为以下几种情况:
- 如果当前节点的前继节点的
waitStatus是否是 -1,则可以阻塞当前线程 - 如果当前节点的前继节点的
waitStatus是否是大于零,即值为 1,说明是取消了的,很可能前继的前继节点也是取消了的,于是触发取消节点的清理操作,这个设计很有意思,按我理解是用了一种类似懒加载的被动触发的思想。 - 如果当前节点的是 0 或 -2 等其他什么值,那么就将该值改成 -1,表示当前线程将进行阻塞,其前继节点释放同步状态时,需要唤醒它,这种情况出现在队列初始化或清空后,哨兵节点的
waitStatus为 0。acquireQueued的下一次自旋获取锁失败的话将会走进 shouldParkAfterFailedAcquire 方法的第一个判断ws == Node.SIGNAL,由于满足阻塞条件,当前线程阻塞。
|
|
而阻塞的代码相对比较好理解,除了 Thread.interrupted() 这句,我们先留个问题的引子,以后再回看。
|
|
1.2 释放同步状态
AbstractQueuedSynchronizer 独占模式下的同步状态的释放过程在 release 方法中,它是一个模板方法,钩子函数实现具体的释放过程,返回值代表是否释放成功,如果释放成功,则看队列有没有初始化,有则需要调用 unparkSuccessor 唤醒一个线程。
|
|
注意这里的判断 h != null && h.waitStatus != 0 ,h != null 代表队列已经初始化了,那么 h.waitStatus != 0 怎么理解呢?如果 waitStatus 等于 0,说明没有线程 park,也就是说没有线程需要被唤醒。unparkSuccessor 方法采用倒序获取队列中可唤醒的线程,然后将之唤醒,至于为什么采用倒序而不是从前往后遍历,我们后面探讨。
|
|
2. 共享模式
共享模式下,多个线程可以同时持有同步状态,state 字段的大小往往代表有多少个线程共享该同步状态,异步转同步工具 CountDownLatch 就是基于 AbstractQueuedSynchronizer 的共享模式实现。
在独占模式下,只有等持有同步状态的线程释放同步状态,才会取唤醒等待队列的第一个非哨兵可唤醒线程 t,t 会自旋获取同步状态。但是在共享模式下,线程 t 获取同步状态时,如果获取成功,将会唤醒等待队列的线程来获取同步状态,也就是说同步状态的获取和释放都可能触发等待队列后继节点的唤醒,而且共享模式下,会尝试唤醒所有后继节点。
1.1 获取同步状态
独占模式下同步状态的获取定义在下面的模板方法中,但是与独占模式的同步状态获取不同,钩子函数 tryAcquireShared 的返回值是整型而不是布尔类型的,它的返回值取值范围包括:
- 大于 0:当前线程获取同步状态成功,同时同步状态未共享完毕,其他线程仍有可能获取到。
- 等于 0:当前线程获取同步状态成功,同时同步状态共享完,其他线程不能再获取到,需要等待。
- 小于 0:当前线程获取同步状态失败,当前线程将入队。
当然上述的约束并不是严谨的,CountDownLatch 在此处不会返回 0。
|
|
doAcquireShared 主要经过以下几个步骤:
- 节点化当前线程并入队
- 如果当前节点的前继节点是哨兵,则再次调用
tryAcquireShared获取同步状态,如果返回值成功,则继续调用setHeadAndPropagate方法,setHeadAndPropagate比较复杂,主要的作用是将等待队列中此刻在等待的线程逐一唤醒去获取同步状态。 - 如果当前节点的前继节点不是哨兵。则处理方式与
acquireQueued方法一样,主要将前继节点的等待状态记为 -1,然后阻塞。
|
|
由于当前线程获取到锁了,所以 setHeadAndPropagate 会先将当前节点设置为哨兵节点,并记录旧哨兵,接下来的第一个 if 的判断很复杂,分情况探究,注意传进来的 propagate 必定大于或等于 0。
- 判断为 true:
propagate > 0:说明当前线程获取到同步状态后,其他线程还能继续获取到,则会尝试唤醒等待队列中的其他线程。propagate == 0 && h == null:没有剩余的共享资源可获取,同时等待队列未初始化,则再次确认判断当前节点(新的哨兵节点)后面在这一秒附近有没有新插入共享型的后继节点,有则唤醒它们。propagate == 0 && h != null && h.waitStatus < 0:没有剩余的共享资源可获取,同时等待队列已初始化,则说明原等待队列其实没有其他线程在等待,则再次确认判断当前节点(新的哨兵节点)后面在这一秒附近有没有新插入共享型的后继节点,有则唤醒它们。
- 判断为 false:
propagate == 0 && h != null && h.waitStatus >= 0 && (h = head) != null && h.waitStatus >= 0:同步状态共享完毕,后来的线程需等待,原来的队列已经初始化,旧哨兵不为空且其waitStatus大于或等于 0,即取消或无线程在等待,
|
|
写到这里我开始问自己,为什么都没有资源可获取了,还要取唤醒等待队列中的节点来获取呢?我想作者大概有种赌博的心态,即“既然这个线程能拿到了一个共享资源,说不定接下来就像天上掉馅饼一样,其他共享资源也都被释放了,有这样的好事肯定要和跟着我的这一批兄弟说,叫他们先醒来,做好发达准备。”
1.2 释放同步状态
释放同步状态的逻辑定义在模板方法 releaseShared 中,其中钩子函数 tryReleaseShared 由子类去实现,如果同步状态完全释放,则会触发 doReleaseShared 逻辑。
|
|
再看 doReleaseShared 方法,当同步状态全都被释放时,将会进入该方法,其中主要的判断:
- 如果队列不为空,判断哨兵的等待状态,如果是 SIGNAL,则唤醒其后继节点,注意如果唤醒失败就 continue,但是唤醒成功也仍然没有跳出循环,这时我们转换到
AbstractQueuedSynchronizer中线程阻塞的地方acquireQueued方法,第一个非哨兵非取消节点被唤醒,并将原头节点删除,所以下面的代码的当下一轮迭代进来时将会继续往后唤醒线程,直到整个队列为空。 - 如果队列为空,则结束。
这个方法是在同步状态(完全或部分)释放时调用的,这时就会把等待队列中的线程逐一唤醒,让它们都有机会去获取到同步状态。注意最后一个 h == head 判断,如果 unpark 唤醒的后继节点仍然抢不到同步状态,那么就会退出这里的循环,而不是一直运转。
|
|
对于 unparkSuccessor 方法,其中会从队列的尾部往前找 waitStatus 小于等于 0 的节点,直到找到的节点最接近哨兵节点,找到就会将之 unpark,至于为什么不是从前往后遍历我们后续探讨。
|
|
三、实例场景
下面我们通过运行源码看 AbstractQueuedSynchronizer 的运作过程是否和分析的一致。我们自己实现一个不可重入的非公平独占锁,如下所示:
|
|
假设有 6 条线程,其中线程 t0 在获取到同步状态后陷入睡眠,此后的连续时间内,有 5 条线程依次进入 lock 方法尝试获取同步状态,但因为都失败并进行排队。
|
|
为了直观看到等待队列的情况,我重写了 Node 的 toString 方法,在其中打印了当前节点的一些关键信息,我们在线程调用阻塞方法时,打印当前 AbstractQueuedSynchronizer 对象的 private transient volatile Node head;,即打印整个等待队列的信息。
|
|
下面是输出,可以看到 [] 中输出了队列中每个节点的情况,其中第一个数字代表节点的 waitStatus,后一个信息代表节点中封装的线程。
INFO [t1] - 进入休眠,此时队列情况 => aqs: [-1, null] <=> [0, t1]
INFO [t2] - 进入休眠,此时队列情况 => aqs: [-1, null] <=> [-1, t1] <=> [0, t2]
INFO [t3] - 进入休眠,此时队列情况 => aqs: [-1, null] <=> [-1, t1] <=> [-1, t2] <=> [0, t3]
INFO [t4] - 进入休眠,此时队列情况 => aqs: [-1, null] <=> [-1, t1] <=> [-1, t2] <=> [-1, t3] <=> [0, t4]
INFO [t5] - 进入休眠,此时队列情况 => aqs: [-1, null] <=> [-1, t1] <=> [-1, t2] <=> [-1, t3] <=> [-1, t4] <=> [0, t5]
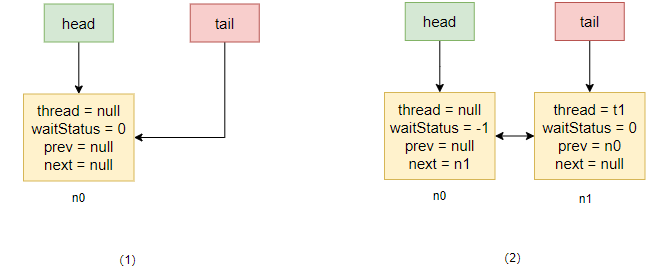
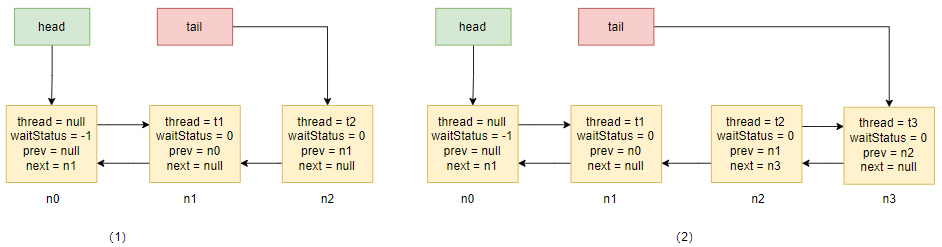
上述过程获取同步状态顺序情况如下图所示:首先由于 t0 获取到同步状态后一直没有释放,所以后续的线程在 CAS 失败后都需要排队,当 t1 进入 addWaiter 后会进入 enq 方法创建一个哨兵节点,如图(1)所示,然后将当前线程节点化追加到其后,并且将前继节点的 waitStatus 改成 -1,然后自己阻塞,如图(2)所示。
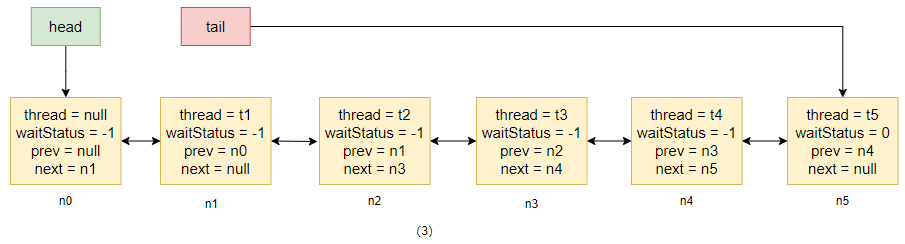
后续的四条线程与 t1 的情况一样,也依次入队,当 t5 入队后,整个等待队列的情况如图(3)所示。
我们注意到上面的过程中有一些细节:
- 等待队列是一个双向队列,每个节点存储线程、前后继节点、
waitStatus等信息。 - 等待队列的头节点不存储线程,只作哨兵用。
- 没有获取到同步状态的线程采用尾插法排队。
- 线程入队除了维护前后继节点的关系外,还会将前继节点的
waitStatus从 0 改成 -1
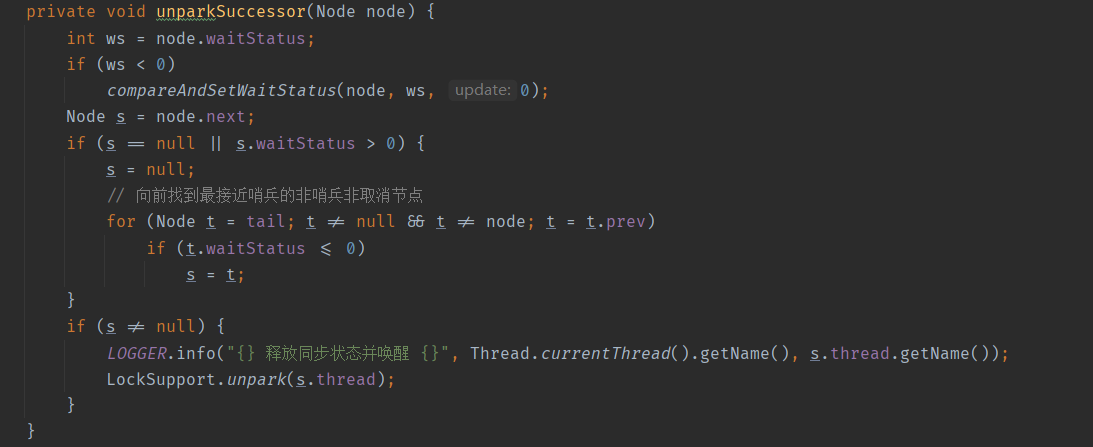
七秒后 t0 释放同步状态,在释放同步状态的地方会调用 unparkSuccessor 方法,其中会拿到离哨兵最近的非取消非哨兵节点,然后将之唤醒,我们在唤醒时打印日志。
同时我们在节点入队阻塞的地方打印日志,看被唤醒的线程的执行情况。
然后我们得到的日志如下所示:
INFO [t0] - t0 释放同步状态并唤醒 t1
INFO [t1] - 被唤醒
INFO [t1] - 获取到同步状态 => aqs:[-1, null] <=> [-1, t2] <=> [-1, t3] <=> [-1, t4] <=> [0, t5]
INFO [t1] - t1 释放同步状态并唤醒 t2
INFO [t2] - 被唤醒
INFO [t2] - 获取到同步状态 => aqs:[-1, null] <=> [-1, t3] <=> [-1, t4] <=> [0, t5]
INFO [t2] - t2 释放同步状态并唤醒 t3
INFO [t3] - 被唤醒
INFO [t3] - 获取到同步状态 => aqs:[-1, null] <=> [-1, t4] <=> [0, t5]
INFO [t3] - t3 释放同步状态并唤醒 t4
INFO [t4] - 被唤醒
INFO [t4] - 获取到同步状态 => aqs:[-1, null] <=> [0, t5]
INFO [t4] - t4 释放同步状态并唤醒 t5
INFO [t5] - 被唤醒
INFO [t5] - 获取到同步状态 => aqs:[0, null]
t5 释放同步状态时 head 的 waitStatus 为 0,后续没有需要被唤醒的线程,所以没有打印 “t5 释放同步状态并唤醒 xx” 的日志。当 t0 释放锁唤醒 t1 后,t1 将会在 acquireQueued 中尝试获取同步状态,如果能获取到,则会将原哨兵节点从队列中删除,然后当前节点的线程置空,从而成为新哨兵。
依此类推,直到最后 t5 获取到同步状态并将当前节点哨兵化,整个队列又回到最初只有一个哨兵节点的状态。当然上述的程序中各个线程是按序启动的,但实际上多线程都是并发竞争同步状态的,对于非公平锁,当一个节点被唤醒时它不一定能 CAS 成功,从而会继续休眠,等待下一次被唤醒。
四、常见问题
为了加深理解,下面针对自己想到或者别人提到的一些相关问题进行探讨。
1. 为什么设置尾节点需要使用 CAS 设置头节点的时候不用呢?
因为调用设置头节点的线程是获取到锁的,而任一时间内只有一条线程能拿到锁,所以不会存在其他线程与之并发,所以不需要使用 CAS 的方式 setHead。
2. 为什么唤醒线程时遍历队列不从头节点向后遍历?
当独占锁的线程释放锁时,将会采用逆序遍历的方式获取距离哨兵节点的最近的第一个非取消非哨兵节点作为唤醒的对象,代码在 unparkSuccessor 中:
|
|
在探讨作者的设计初衷前,如果让你实现这个方法时,你会怎么写呢?假如写成下面这样顺序遍历的方式会存在什么问题呢?
|
|
在多线程并发情况下,当一条线程在唤醒后继节点的同时,很可能会有其他线程在尝试加入等待队列,我们再回到 addWaiter 方法,
|
|
考虑这样一种场景,我们不妨假设是在独占的公平竞争情况下:
- 队列已经初始化,线程 t0 独占着同步状态,后续线程需要入队
- 假如 t1 先来排队,并阻塞
- 接着 t2 来排队,在 addWaiter 中执行完 compareAndSetTail 后很不巧它失去了时间片,那么
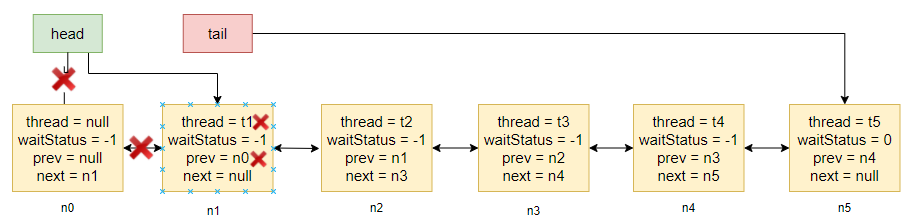
pred.next = node;这一句将迟迟没有执行。 - 接着又有一条线程 t3 来排队,排队完成并默默进入阻塞状态,这时的等待队列情况如下图所示:
- 再接着线程 t0 释放同步状态,执行 unparkSuccessor 方法,这时如果是顺序遍历等待队列,将获取不到要唤醒的线程,因为 t1 线程所在节点的后继节点没有指向。
我们不妨编码来模拟这样的情况,首先我们跟先前的例子一样创建 4 条线程:
|
|
接着我们在入队的地方 addWaiter 方法里通过 sleep 的方式手动让线程 t2 失去时间片,同时我们让 t1 的状态置为取消,因为在 release 方法里有这么一段判断 if (h != null && h.waitStatus != 0),而 t2 已经失去了时间片,还没将前继节点 n1 的 waitStatus 改为 -1。那么当 t0 释放同步状态时,将会唤醒 t1,t1 再释放同步状态时获取到的哨兵节点,判断到 waitStatus 等于 0,将不会调用 unparkSuccessor,而我们实验的目的就是让 t1 调用 unparkSuccessor,看是否能够获取到逻辑上应该获取到的 t2。
而如果我们将 t1 节点取消,那么当 t0 释放同步状态时同样能 unparkSuccessor,但这次将不会唤醒 t1,而是往后继续遍历,这时我们将 unparkSuccessor 换成我们写的顺序遍历的方式,就能看到 t0 获取不到需要唤醒的节点。
|
|
下面是执行代码的输出,由于采用顺序遍历,所以第三行输出后看不到 t2 的信息,但实际上 t2 所在的节点已经入队。在第四行输出看到 t0 释放锁时顺序遍历获取不到需要唤醒的 t2。只有等到 t2 睡醒后自己自旋获取到同步状态。
INFO [t1] - 进入休眠,此时队列情况 => aqs: [-1, null] <=> [0, t1]
INFO [t2] - 将 t1 的状态改为取消
INFO [t3] - 进入休眠,此时队列情况 => aqs: [-1, null] <=> [1, t1]
INFO [t0] - unparkSuccessor null
INFO [t2] - 睡醒了
INFO [t2] - 获取到同步状态 => aqs:[-1, null] <=> [0, t3]
INFO [t2] - unparkSuccessor t3
INFO [t2] - t2 释放同步状态并唤醒 t3
INFO [t3] - 被唤醒
INFO [t3] - 获取到同步状态 => aqs:[0, null]